Linternals: The Slab Allocator

The monthly blog schedule has gone somewhat awry, but fear not, today we’re diving back into our Linternals series on memory allocators!
I know it’s been a while, I’ve been sidetracked with the new job and some cool personal projects, so let’s quickly highlight what we covered last time:
- what we mean by memory allocators
- key memory concepts such as pages, page frames, nodes and zones
- piecing this together to explain the underlying allocator used by the Linux kernel, the buddy (or page) allocator, as well as touching on it’s API, pros and cons
This time we’re going to build on that and introduce another memory allocator found within the Linux kernel, the slab allocator, and it’s various flavours. So buckle up as we dive into the exciting world of SLABs, SLUBs and SLOBs.

Contents
0x03 The Slab Allocator
The slab allocator is the another memory allocator used by the Linux kernel and, as we touched on last time, “sits on top of the buddy allocator”.
What I mean by this, is that while the slab allocator is another kernel memory allocator it doesn’t replace the buddy allocator. Instead it introduces a new API and features for kernel developers (which we’ll cover soon), but under the hood it uses the buddy allocator too.
So why use the slab allocator? Well, last time we touched on some of the issues and drawbacks with the buddy allocator. The purpose of the slab allocator is to[1]:
- reduce internal fragmentation,
- cache commonly used objects,
- better utilise of hardware cache by aligning objects to the L1 or L2 caches
So while the buddy allocator excels at allocating large chunks of physically contiguous memory, the slab allocator provides better performance to kernel developers for smaller and more common allocations (which happen more often than you might think!).
Before we dive into some more detail and explain how the kernel’s slab allocator achieves this, I should highlight that the term “slab allocator” refers to a generic memory management implementation.
The Linux kernel actually has three such implementations: SLAB[2], SLUB and SLOB. SLUB is what you’re likely to see on modern desktops and servers[3], so we’ll be focusing on this implementation through out this post, but I’ll touch on the others later.
If you’re interested in its origins, slab allocation was first introduced by Jeff Bonwick back in the 90’s and you can read his paper “The Slab Allocator: An Object-Caching Kernel Memory Allocator” over on USENIX.[4] [5]
- https://www.kernel.org/doc/gorman/html/understand/understand011.html
- Note that “slab allocator” != “slab” != “SLAB”, confusing ik
- SLUB has been the default since 2.6.23 (~2008), so by likely I mean very likely
- http://www.usenix.org/publications/library/proceedings/bos94/full_papers/bonwick.ps
- Thanks @[email protected] for the reminder to include this here :)
The Basics

At a high level, there’s 3 main parts to the SLUB allocator: caches, slabs and objects.
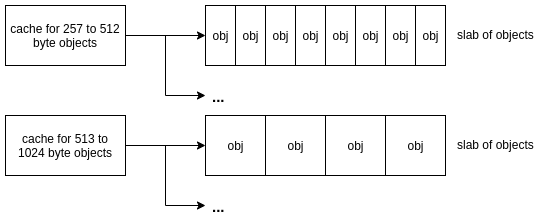
As we can see, these form a pretty straightforward hierarchy. Objects (i.e. stuff being allocated by the kernel) of a particular type or size are organised into caches.
Objects belonging to a cache are further grouped into slabs, which will be of a fixed size and contain a fixed number of objects.
Objects in this context are just allocations of a particular size. For example, when a process opens a seq_file[1] in Linux, the kernel will allocate space for [struct seq_operations](https://elixir.bootlin.com/linux/v6.0.6/source/include/linux/seq_file.h#L32) using the slab allocator API. This is will be a 32 byte object.
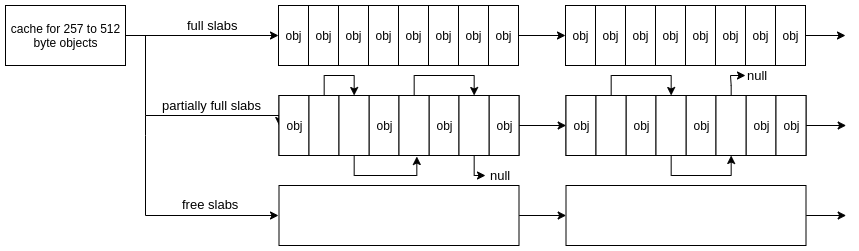
Among other things, the cache will keep tabs on which slabs are full, which slabs a partially full and when slabs are empty. Free objects within a slab will form a linked list, pointing to the next free object within that slab.
So when the kernel wants to make an allocation via the SLUB allocator, it will find the right cache (depending on type/size) and then find a partial slab to allocate that object.
If there are no partial or free slabs, the SLUB allocator will allocate some new slabs via the buddy allocator. Yep, there it is, we’re full circle now. The slabs themselves are allocated and freed using the buddy allocator we touched on last time.
Knowing this we can deduce that each slab is at least PAGE_SIZE bytes and is physically contiguous; we’ll touch more on the details in a bit!
Data Structures

In the last section we covered slab allocator 101 - a simplified overview of caches, slabs and objects. Surprise, surprise: the kernel implementation is a tad more complex!
I think the approach I’ll take here is to just dive right into the data structures behind the SLUB implementation and we’ll expand from there and see how it goes?!
So let’s give a quick overview at some of the kernel data structures we’re interested in when looking at the SLUB implementation:
[struct kmem_cache](https://elixir.bootlin.com/linux/v6.0.6/source/include/linux/slub_def.h#L90): represents a specific cache of objects, storing all the metadata and info necessary for managing the cache[struct kmem_cache_cpu](https://elixir.bootlin.com/linux/v6.0.6/source/include/linux/slub_def.h#L48): this is a per-cpu structure which represents the “active” slab for a particularkmem_cacheon that CPU (I’ll explain this soon, dw!)[struct kmem_cache_node](https://elixir.bootlin.com/linux/v6.0.6/source/mm/slab.h#L741): this is a per-node (NUMA node) structure which tracks the partial and full slabs for a particularkmem_cacheon that node that aren’t currently “active”[struct slab](https://elixir.bootlin.com/linux/v6.0.6/source/mm/slab.h#L9): this structure, as you probably guessed, represents an individual slab and was introduced in 5.17[1] (previously this information would be accessed directly from[struct page](https://elixir.bootlin.com/linux/v5.17/source/include/linux/mm_types.h#L72), but more on that soon!)
struct kmem_cache
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
slab_flags_t flags;
unsigned long min_partial;
unsigned int size;
unsigned int object_size;
struct reciprocal_value reciprocal_size;
unsigned int offset;
#ifdef CONFIG_SLUB_CPU_PARTIAL
unsigned int cpu_partial;
unsigned int cpu_partial_slabs;
#endif
struct kmem_cache_order_objects oo;
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects min;
gfp_t allocflags;
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *);
...
const char *name; /* Name (only for display!) */
struct list_head list; /* List of slab caches */
...
struct kmem_cache_node *node[MAX_NUMNODES];
};
comments stripped for redundancy, from /include/linux/slub_def.h
As you might expect from the structure that underpins the SLUB allocator’s cache implementation, there’s a lot to unpack here! Let’s break down the key bits.
name stores the printable name for the cache, e.g. seen in the command slabtop (we’ll cover introspection more later). Nothing wild here.
object_size is the size, in bytes, of the objects (read: allocations) in this cache excluding metadata. Wheras size is the size, in bytes, including any metadata. Typically there is no additional metadata stored in SLUB objects, so these will be the same.
flags holds the flags that can be set when creating a kmem_cache object. I won’t go in to detail, but these can be used for debugging, error handling, alignment etc. [2]
[struct kmem_cache_order_objects](https://elixir.bootlin.com/linux/v6.0.6/source/include/linux/slub_def.h#L83) oo is a neat word-sized structure that simply contains one member: unsigned int x.
This is used to store both the order[3] of the slabs in this cache (in the upper bits) and the number of objects that they can contain (in the lower bits). There are then helpers to fetch either of these values ([oo_objects()](https://elixir.bootlin.com/linux/v6.0.6/source/mm/slub.c#L419) and [oo_order()](https://elixir.bootlin.com/linux/v6.0.6/source/mm/slub.c#L414)).
min I believe stores the minimum oo counts for slabs without any debugging or extra metadata enabled. Such that when enabling those features, the kernel can compare if oo has increased from min and decided whether to still enable them if desired.
reciprocal_size is, well, the reciprocal of size. If you also don’t math, this is basically the properly calculated value of 1/size. This is used by [obj_to_index()](https://elixir.bootlin.com/linux/v6.0.6/source/include/linux/slub_def.h#L179) for determining the index of an object within a slab.
list is a linked list of all struct kmem_cache on the system and is exported as [slab_caches](https://elixir.bootlin.com/linux/v6.0.6/source/mm/slab.h#L258).

So far we’ve covered some of the main metadata, but now we’ll dive into some of the members involved in actually facilitating allocations.
cpu_slab is a per CPU reference to a [struct kmem_cache_cpu](https://elixir.bootlin.com/linux/v6.0.6/source/include/linux/slub_def.h#L48). This means that under-the-hood this is an array of sorts and each CPU uses a different index[4], thus having a reference to a different [struct kmem_cache_cpu](https://elixir.bootlin.com/linux/v6.0.6/source/include/linux/slub_def.h#L48).
We’ll touch more in this structure soon, but it represents the “active” slab for a given CPU. This means that any allocations made by a CPU will come from this slab (or at least this slab will be checked first!).
node[MAX_NUMNODES] on the other hand is a per node reference to a [struct kmem_cache_node](https://elixir.bootlin.com/linux/v6.0.6/source/mm/slab.h#L741). This structure holds information on all the other slabs (partial, full etc.) within this node and is the next port of call after cpu_slab.
min_partial defines the minimum number of slabs in a partial list, even if they’re empty. Typically when a slab is empty, it will be freed back to the buddy allocator, unless there is min_partial or less slabs in the partial list!
offset stores the “free pointer offset”. My educated guess is that this is the byte offset into an object where the free pointer (i.e. pointer to next free object in the slab) is found. This would usually be zero and probably changes with debugging/flag tweaks.
[CONFIG_SLUB_CPU_PARTIAL](https://cateee.net/lkddb/web-lkddb/SLUB_CPU_PARTIAL.html) enables [struct kmem_cache_cpu](https://elixir.bootlin.com/linux/v6.0.6/source/include/linux/slub_def.h#L48) to not just track a per CPU “active” slab but also have its own per CPU partial list. After explaining the roles of cpu_slab and node[] the benefits should become clearer.
cpu_partial and cpu_partial_slabs define the number of partial objects and partial slabs to keep around.
allocflags allows a cache to define GFP flags[5] to apply to allocations, which can determine allocator behaviour. These can also be added through the allocation API.
ctor() lets the cache define a constructor to be called on the object during [setup_object()](https://elixir.bootlin.com/linux/v6.0.6/source/mm/slub.c#L1806) which is called when a new slab is allocated.

And that’s more or less all the key fields in kmem_cache! Hopefully that provided some additional context around the main structure underpinning the cache implementation, and we can dive into the next two with enough context to get along.
There’s of course some fields I missed out, associated with debugging, mitigations or other bits and pieces that probably didn’t justify the bloat but I may come back to some time.
struct kmem_cache_cpu
struct kmem_cache_cpu {
void **freelist; /* Pointer to next available object */
unsigned long tid; /* Globally unique transaction id */
struct slab *slab; /* The slab from which we are allocating */
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct slab *partial; /* Partially allocated frozen slabs */
#endif
local_lock_t lock; /* Protects the fields above */
#ifdef CONFIG_SLUB_STATS
unsigned stat[NR_SLUB_STAT_ITEMS];
#endif
};
Bet you’re breathing a sigh of relief at that 12 liner, eh? I know I am writing this lol. Anyway, let’s dive into [struct kmem_cache_cpu](https://elixir.bootlin.com/linux/v6.0.6/source/include/linux/slub_def.h#L48), which tracks an active slab (and partial list) for a specific CPU.
freelist points to the next available (free) object in the active slab, slab. This is a void ** as each free object contains a pointer to the next free object in the slab.
slab points to the [struct slab](https://elixir.bootlin.com/linux/v6.0.6/source/mm/slab.h#L9) representing the “active” slab, i.e. the slab from which we’re allocating from for this CPU. We’ll explore this more soon.
partial is the per cpu partial list we mentioned earlier, when [CONFIG_SLUB_CPU_PARTIAL](https://cateee.net/lkddb/web-lkddb/SLUB_CPU_PARTIAL.html) is enabled (it should be on server/desktop). This points to a list of partially full [struct slab](https://elixir.bootlin.com/linux/v6.0.6/source/mm/slab.h#L9).

u and me both
Okay so let’s move away from dry member descriptions and actually look at some examples of how SLUB might serve an allocation request!
In this example lets say a kernel driver has requested to allocate a 512 byte object via the SLUB allocator API (spoiler: it’s kmalloc()), from the general purpose cache for 512 byte objects, kmalloc-512. There’s a couple of ways this can do down!
If cache->cpu_slab->slab has several free objects, things are fairly simple. The address of the object pointed to by cache->cpu_slab->freelist will be returned to the caller.
The freelist will be updated to point to the next free object in cache->cpu_slab->slab and relevant metadata will be updated regarding this allocation.
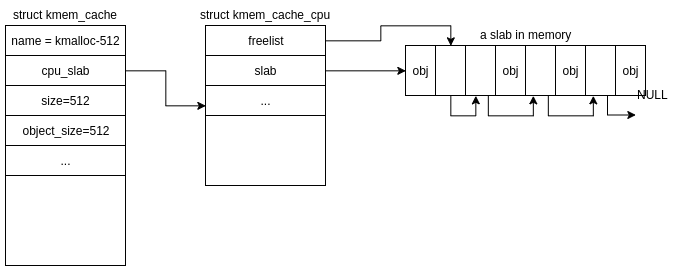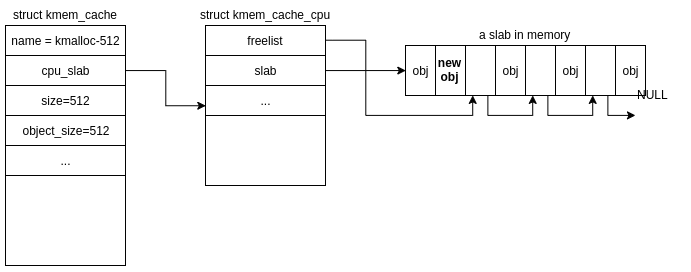
the addr of new obj is returned to the caller
Before we dive into other allocation scenarios, let’s cover one more structure (sorry)!
struct kmem_cache_node
struct kmem_cache_node {
spinlock_t list_lock;
unsigned long nr_partial;
struct list_head partial;
#ifdef CONFIG_SLUB_DEBUG
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
#endif
};
We’re almost their folks! This structure tracks the partially full (partial) and full slabs for a particular node. We’re talking about NUMA nodes here, which we very briefly touched on in the last post.
The tl;dr here is many CPUs can belong to one node. You can see your node information on Linux with the command numactl -H, which will let you know how many nodes you have and the CPUs that belong to each node!
partial is a linked list of partially full struct slabs. The number of which is tracked by nr_partial, which should always be greater or equal than kmem_cache->min_partial, as we touched on earlier.
full is a linked list of full struct slabs. Not much else to say about that!
nr_slabs is the total number of slabs tracked by this kmem_cache_node. Similarly, total_objects tracks the total number of allocated objects.

So now we have more context about the internal SLUB structures, let’s take what we know and apply that to a different allocation path, using the scenario from before.
If the new obj returned to the caller is the last free object in cache->cpu_slab->slab, the “active” slab is moved into it’s node’s full list. The first slab from cache->cpu_slab->partial is then made the “active” slab.
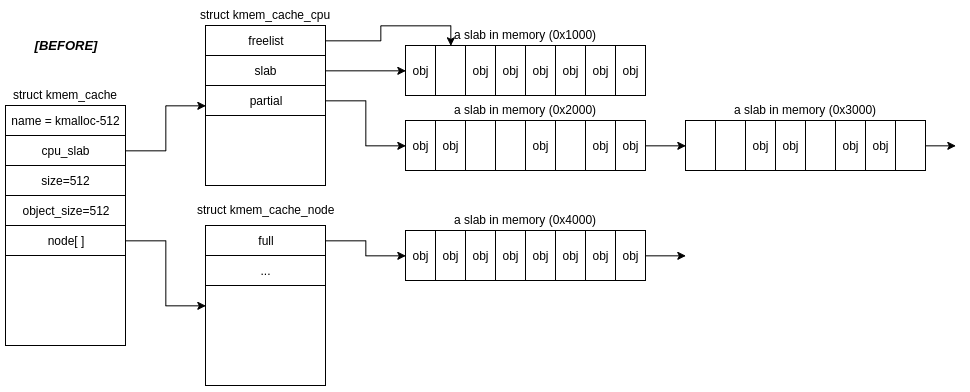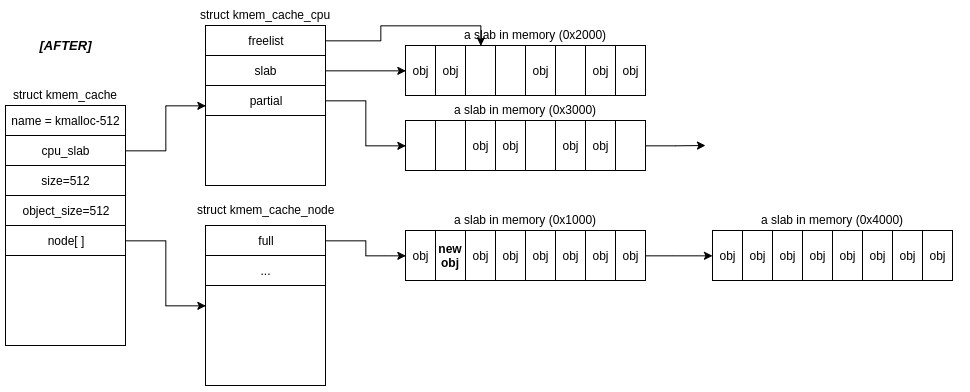
As you can imagine, there’s many potential allocation paths depending on the internal cache state. Similarly, there are multiple paths when an object is freed.
I won’t walk through all the possible cases here, but hopefully this post provides enough details to fill in the blanks!
struct slab
struct slab {
unsigned long __page_flags;
union {
struct list_head slab_list;
struct rcu_head rcu_head;
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct {
struct slab *next;
int slabs; /* Nr of slabs left */
};
#endif
};
struct kmem_cache *slab_cache;
/* Double-word boundary */
void *freelist; /* first free object */
union {
unsigned long counters;
struct {
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
};
unsigned int __unused;
atomic_t __page_refcount;
#ifdef CONFIG_MEMCG
unsigned long memcg_data;
#endif
};
Last, but certainly not least, on our SLUB struct tour is struct slab. This structure, unsurprisingly, represents a slab. Seems pretty straightforward, right?
Well, despite it’s benign look, struct slab is hiding something. It’s actually a struct page in disguise. Wait, what?
Until recently (5.17)[6], a slab’s metadata was accessed directly via a union in the struct page which represented the slabs memory[7].
While that slab information is still stored in struct page, as an effort to decouple things from struct page, struct slab was created to move away from using struct page with the aim to move the information out of struct page entirely in the future.

Anyway, with that little bit of excitement out the way, let’s see what some of these fields within struct page, uh I mean struct slab are saying!
The first union can contain several things: slab_list, the linked list this slab belongs in, e.g. the node’s full list; a struct for CPU partial slabs where next is the next CPU partial slab and slabs is the number of slabs left in the CPU partial list.
slab_cache is a reference to the struct kmem_cache this slab belongs to.
freelist is a pointer to the first free object in this slab.
Then we have another union, this time used to view the same data in different ways. counters is used to fetch the counters within the struct easily, whereas the struct allows granular access to each of the counters: inuse, objects, frozen.
objects is a 15-bit counter defining the total number of objects in the slab, while inuse is a 16-bit counter use to track the number of objects in the slab being used (i.e. have been allocated and not freed).
frozen is a boolean flag that tells SLUB whether the slab has been frozen or not. Frozen slabs are “exempt from list management. It is not on any list except per cpu partial list. The processor that froze the slab is the one who can perform list operations on the slab”.[8]
CONFIG_MEMCG “provides control over the memory footprint of tasks in a cgroup”[9]. Part of this includes accounting kernel memory for memory cgroups (memcgs)[10]. Allocations made with the GFP flag GFP_KERNEL_ACCOUNT are accounted.
memcg_data is used when accounting is enabled to store “the object cgroups vector associated with a slab”[11].
Wrap-up

Whew, that was quite the knowledge dump! If you read through that start-to-finish then kudos to you cos that’s a lot to take in; hopefully it’s not too dry.
The aim of this section was to provide a decent foundational understanding of the SLUB allocator as seen in modern Linux kernels by exploring the core data structures used in it’s implementation and exploring how they fit together.
Next up we’ll use this to take a look at the API and how the SLUB allocator can be used by other parts of the kernel. A bit later we’ll also touch on some introspection, if you want to get some hands on and explore some of these data structures and stuff.
- https://lwn.net/Articles/881039/
- https://elixir.bootlin.com/linux/v6.0.6/source/include/linux/slab.h#L23
- Remember page order sizes from the previous section? A 0x1000 byte slab is an order 0 slab (20 pages).
- https://lwn.net/Articles/452884/
- https://www.kernel.org/doc/html/latest/core-api/memory-allocation.html
- https://lwn.net/Articles/881039/
- we’ll remember from previous posts that there is a
struct pagefor every physical page of memory that the kernel manages - https://elixir.bootlin.com/linux/v6.0.6/source/mm/slub.c#L74
- https://cateee.net/lkddb/web-lkddb/MEMCG.html
- https://www.kernel.org/doc/Documentation/cgroup-v1/memory.txt
- https://elixir.bootlin.com/linux/v6.0.6/source/mm/slab.h#L433
The API

Thought you were done with kernel code? Hah! Think again. Time to take our understanding of the kernel’s SLUB allocator and explore it’s API.
Like all my posts, this is pretty adhoc, so if I get excited we might take a deeper look into some of the allocator functions and have a peek at the implementation.
It’s worth highlighting again that there are three slab allocator implementations in the Linux kernel: SLAB, SLUB & SLOB. They share the same API, so as to abstract the implementation from the rest of the kernel.
As you might expect, be prepared for plenty of #ifdefs when perusing the source! The starting point for which is probably going to be [include/linux/slab.h](https://elixir.bootlin.com/linux/v6.0.6/source/include/linux/slab.h).
kmalloc & kfree
void *kmalloc(size_t size, gfp_t flags)
The bread and butter of the slab allocator API, kmalloc(), as the name implies, is essentially the kernel equivalent of C’s malloc().
It allows a kernel developer to request a memory allocation of size bytes, on a success the function will return a pointer to the allocated memory and error code[1] on a failure.
static __always_inline __alloc_size(1) void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size)) {
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags);
}
return __kmalloc(size, flags);
}
We can see the generic kmalloc() definition is a wrapper around __kmalloc() which is prototyped in slab.h, but the definition is slab implementation specific.
The kmalloc() wrapper essentially hands off large allocations (defined by [KMALLOC_MAX_CACHE_SIZE](https://elixir.bootlin.com/linux/v6.0.6/source/include/linux/slab.h#L290)) to a separate function: [kmalloc_large()](https://elixir.bootlin.com/linux/v6.0.6/source/include/linux/slab.h#L526) which in fact calls the underlying buddy allocator to serve large allocations!
Otherwise, [__kmalloc()](https://elixir.bootlin.com/linux/v6.0.6/source/include/linux/slab.h#L434) is called, who’s implementation can be found in [/mm/slub.c](https://elixir.bootlin.com/linux/v6.0.6/source/mm/slub.c#L4412).
void *__kmalloc(size_t size, gfp_t flags) {
struct kmem_cache *s;
void *ret;
...
s = kmalloc_slab(size, flags); [0]
...
}
Bringing things back round to the SLUB allocator, if this is making an allocation of size bytes - what kmem_cache is it allocating from? Good question!
By default the kernel creates an array of general purpose kmem_caches depending on the “kmalloc type” (derived from flags) and the allocation size.
These caches are mainly created via [create_kmalloc_caches()](https://elixir.bootlin.com/linux/v6.0.6/source/mm/slab_common.c#L875) and stored in the exported symbol [kmalloc_caches](https://elixir.bootlin.com/linux/v6.0.6/source/include/linux/slab.h#L339):
extern struct kmem_cache *
kmalloc_caches[NR_KMALLOC_TYPES][KMALLOC_SHIFT_HIGH + 1];
So to answer our question: kmalloc() will determine which kmem_cache to allocate from by using the flags and sizes arguments to index into kmalloc_caches:
return kmalloc_caches[kmalloc_type(flags)][index];
The index is above is derived from size. The general purpose cache size-to-index can be seen via the [__kmalloc_index()](https://elixir.bootlin.com/linux/v6.0.6/source/include/linux/slab.h#L386) definition.
This tells us the size of the objects in each kmem_cache, e.g. the kmem_cache for 256 byte objects will be at index 8.
Note that a kmalloc() allocation will use the smallest kmem_cache object size it can fit into. E.g. a 257 byte allocation won’t fit into the 256 byte objects, so it will allocate from the next cache after, which is 512 byte objects.

void kfree(const void *objp)
Before you go throwing kmalloc()’s left and right, don’t forget kfree()! This is of course the ubiquitous function for freeing memory allocated via the slab allocator.
Calling this function on an object allocated via the slab allocator will free that object. If this slab was in the full list, it becomes partial and if this is the last object then the slab may get released altogether.
kmem_cache_create
struct kmem_cache *kmem_cache_create(const char *name, unsigned int size,
unsigned int align, slab_flags_t flags,
void (*ctor)(void *));
So we’ve covered the fundamentals: allocating and freeing via the slab allocator. kmem_cache_create() allows kernel developers to create their own kmem_cache within the slab allocator - pretty neat, right?
Creating a special-purpose cache can be advantageous, especially for objects which are allocated often (like struct task_struct):
- We can reduce internal fragmentation by specifying the object size to suit our needs, as the general purpose caches have fixed object sizes which may not be optimal
ctor()allows us to optimise initialisation of our objects if values are being reused- There’s also debugging, security and other benefits to this but you get the gist!
We can actually use Elixr to see all the references to kmem_cache_create() in the kernel to see who’s making use of this too!
kmem_cache_alloc
void *kmem_cache_alloc(struct kmem_cache *s, gfp_t flags) __assume_slab_alignment __malloc;
Once we’ve created a kmem_cache, we can use kmem_cache_alloc() to allocate an object directly from that cache. You’ll notice here we don’t supply a size, as caches have fixed sized objects and we’re specifying directly the cache we want to allocate from!
cache aliases
Something I haven’t mentioned up until now, is the concept of SLUB aliasing.
To reduce fragmentation, the kernel may “merge” caches with similar properties (alignment, size, flags etc.). find_mergeable() implements this meragability check:
struct kmem_cache *find_mergeable(unsigned size, unsigned align,
slab_flags_t flags, const char *name, void (*ctor)(void *));
A special-purpose cache may get merged/aliased with one of the general-purpose caches we touched on earlier, so allocations via kmem_cache_alloc() for a merged cache will actually come from the respective general-purpose cache.
Seeing It In Action

This is where things get fun! In this section we’re gonna take what we’ve learned throughout this post and double check I haven’t been making it all up :D
/proc/slabinfo
Our good ol’ friend [procfs](https://man7.org/linux/man-pages/man5/proc.5.html) is coming in strong again, by providing us [/proc/slabinfo](https://man7.org/linux/man-pages/man5/slabinfo.5.html), providing kernel slab allocator statistics to privileged users.
$ sudo cat /proc/slabinfo
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
...
task_struct 1480 1539 8384 3 8 : tunables 0 0 0 : slabdata 513 513 0
...
dma-kmalloc-512 0 0 512 32 4 : tunables 0 0 0 : slabdata 0 0 0
...
kmalloc-cg-512 1169 1312 512 32 4 : tunables 0 0 0 : slabdata 41 41 0
...
kmalloc-512 40878 43360 512 32 4 : tunables 0 0 0 : slabdata 1355 1355 0
kmalloc-256 21850 21856 256 32 2 : tunables 0 0 0 : slabdata 683 683 0
kmalloc-192 35987 37002 192 21 1 : tunables 0 0 0 : slabdata 1762 1762 0
kmalloc-128 4555 5440 128 32 1 : tunables 0 0 0 : slabdata 170 170 0
snippet from $ sudo cat /proc/slabinfo
This provides some useful information on the various caches on the system. From the snippet above we can see some of the stuff we touched on in the API section!
We can see a private cache, used for struct task_struct named task_struct. Additionally we can see several general purposes caches, of various kmalloc types ( KMALLOC_DMA, KMALLOC_CGROUP and KMALLOC_NORMAL respectively) and sizes.
slabtop
[slabtop](https://man7.org/linux/man-pages/man1/slabtop.1.html) is a neat little tool, and part of the /proc filesystem utilities project, which takes the introspection a step further by providing realtime slab cache information!
Active / Total Objects (% used) : 3479009 / 3524760 (98.7%)
Active / Total Slabs (% used) : 100682 / 100682 (100.0%)
Active / Total Caches (% used) : 130 / 181 (71.8%)
Active / Total Size (% used) : 923525.41K / 936501.10K (98.6%)
Minimum / Average / Maximum Object : 0.01K / 0.27K / 295.07K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
766116 766116 100% 0.10K 19644 39 78576K buffer_head
...
43328 40468 93% 0.50K 1354 32 21664K kmalloc-512
36981 35834 96% 0.19K 1761 21 7044K kmalloc-192
snippet from $ sudo slabtop
slabinfo
Perhaps confusingly, there is also a tool named slabinfo which is provided with the kernel source in tools/vm/slabinfo.c (calling make in tools/vm is all you need to do build this and get stuck in).
To further the confusion, instead of /proc/slabinfo, slabinfo uses /sys/kernel/slab/[1] as it’s source of information. It contains a snapshot of the internal state of the slab allocator which can be processed by slabinfo.
Further to our section on cache aliases earlier, we can use slabinfo -a to see a list of all the current cache aliases on our system!
$ ./slabinfo -a
...
:0000256 <- key_jar
Here we can see the kmem_cache with name "key_jar" is aliased with kmalloc-256.
debugging

Sometime’s you just can’t beat getting stuck into some good ol’ kernel debugging. I’ve covered previously how to get this setup[2], it’s fairly quick to get kernel debugging via gdb up and running on a QEMU/VMWare guest I promise!
After that we can explore to our heart’s content. We can unravel the exported list slab_caches directly, or perhaps break on a call to kmalloc() and see what hits first.
gef➤ b __kmalloc
Breakpoint 2 at 0xffffffff81347240: file mm/slub.c, line 4391.
...
──────────────────────────────────────────────────────────────────────────────────────────────────────── trace ────
[#0] 0xffffffff81347240 → __kmalloc(size=0x108, flags=0xdc0)
[#1] 0xffffffff81c4911c → kmalloc(flags=0xdc0, size=0x108)
[#2] 0xffffffff81c4911c → kzalloc(flags=0xcc0, size=0x108)
[#3] 0xffffffff81c4911c → fib6_info_alloc(gfp_flags=0xcc0, with_fib6_nh=0x1)
[#4] 0xffffffff81c44186 → ip6_route_info_create(cfg=0xffffc900007a7a58, gfp_flags=0xcc0, extack=0xffffc900007a7bb0)
Given I’m ssh’d into my guest, probably unsurprising there’s network stuff kicking about. Look like someone’s requested a 0x108 byte object, and as we’re going through kmalloc() this should end up in one of the general purpose caches.
0x108 is 264 bytes, so that’s just too big for the kmalloc-256 cache, so we should expect an allocation from on of the 512 byte general purpose caches, right? Let’s find out!
void *__kmalloc(size_t size, gfp_t flags)
{
struct kmem_cache *s;
...
s = kmalloc_slab(size, flags);
Looking at the source, we can see the call to kmalloc_slab() will return our cache.
gef➤ disas
Dump of assembler code for function __kmalloc:
=> 0xffffffff81347240 <+0>: nop DWORD PTR [rax+rax*1+0x0]
0xffffffff81347245 <+5>: push rbp
0xffffffff81347246 <+6>: mov rbp,rsp
0xffffffff81347249 <+9>: push r15
0xffffffff8134724b <+11>: push r14
0xffffffff8134724d <+13>: mov r14d,esi
0xffffffff81347250 <+16>: push r13
0xffffffff81347252 <+18>: push r12
0xffffffff81347254 <+20>: push rbx
0xffffffff81347255 <+21>: sub rsp,0x18
0xffffffff81347259 <+25>: mov QWORD PTR [rbp-0x40],rdi
0xffffffff8134725d <+29>: mov rax,QWORD PTR gs:0x28
0xffffffff81347266 <+38>: mov QWORD PTR [rbp-0x30],rax
0xffffffff8134726a <+42>: xor eax,eax
0xffffffff8134726c <+44>: cmp rdi,0x2000
0xffffffff81347273 <+51>: ja 0xffffffff813474d8 <__kmalloc+664>
0xffffffff81347279 <+57>: mov rdi,QWORD PTR [rbp-0x40]
0xffffffff8134727d <+61>: call 0xffffffff812dbe70 <kmalloc_slab>
0xffffffff81347282 <+66>: mov r12,rax
...
Okay, nice, we can see the call to kmalloc_slab() on line 20, so we just need to check the return value after that call :) Cos we’re on x86_64 we know it’ll be in $RAX.
───────────────────────────────────────────────────────────────────────────── registers ────
$rax : 0xffff888100041a00 → 0x0000000000035140 → 0x0000000000035140
...
─────────────────────────────────────────────────────────────────────────── code:x86:64 ────
0xffffffff81347273 <__kmalloc+51> ja 0xffffffff813474d8 <__kmalloc+664>
0xffffffff81347279 <__kmalloc+57> mov rdi, QWORD PTR [rbp-0x40]
0xffffffff8134727d <__kmalloc+61> call 0xffffffff812dbe70 <kmalloc_slab>
→ 0xffffffff81347282 <__kmalloc+66> mov r12, rax
...
───────────────────────────────────────────────────────────────────────────────── trace ────
[#0] 0xffffffff81347282 → __kmalloc(size=0x108, flags=0xdc0)
────────────────────────────────────────────────────────────────────────────────────────────
gef➤ p *(struct kmem_cache*)$rax
$6 = {
...
size = 0x200,
object_size = 0x200,
...
ctor = 0x0 <fixed_percpu_data>,
inuse = 0x200,
...
name = 0xffffffff8297cb4c "kmalloc-512",
And voila! We cast the value returned by kmalloc_slab() as a kmem_cache and just like that we can view the members. We can see the name is indeed kmalloc-512 as we hypothesised and we can also see some of the other fields we touched on :)
Anyway, hopefully that was a fun little demo on how you can reinforce your understanding with a little exploration in the debugger.
I also wanted to highlight [drgn](https://github.com/osandov/drgn) as another debugger to tinker with, which lets you do live introspection & debugging on your kernel. It’s written in python and is very programmable, however I couldn’t get it to find some symbols for this particular demo.
slxbtrace (ebpf)

Now for the grand reveal, the real reason behind this 5,000 word (yikes) post … a cool little tool I’ve been working on for visualising slub allocations :D
Well, this could very well already be a thing, but I’d been sleeping on ebpf for far too long and this seemed like a fun way to explore the tooling.
Without going too much into the ebpf implementation (another post, maybe?!), slxbtrace[3] lets you specify a specific cache size and visualise the cache state. In particular you can highlight allocations from particular call sites, making it a neat tool for helping with heap feng shui during exploit development.
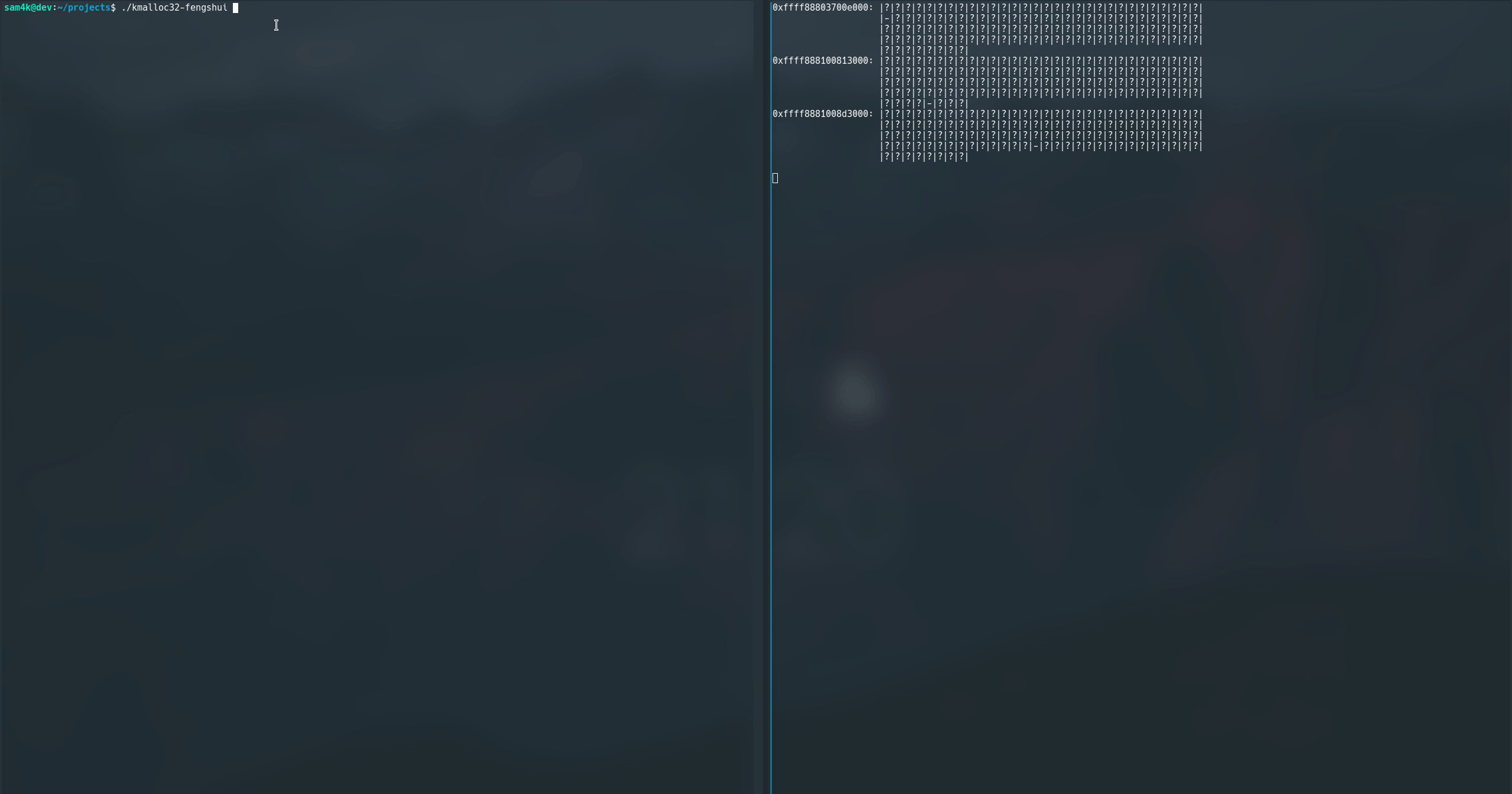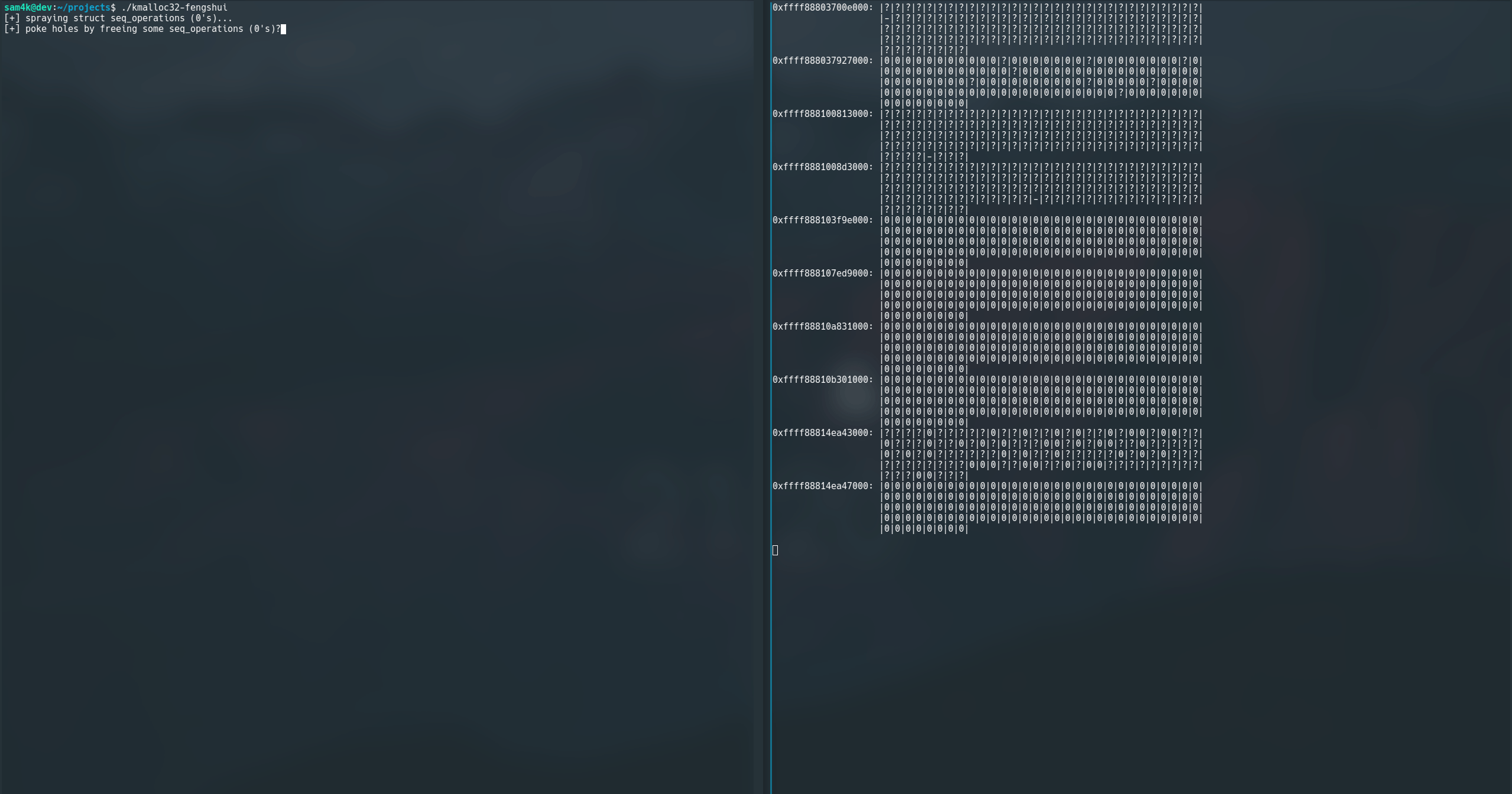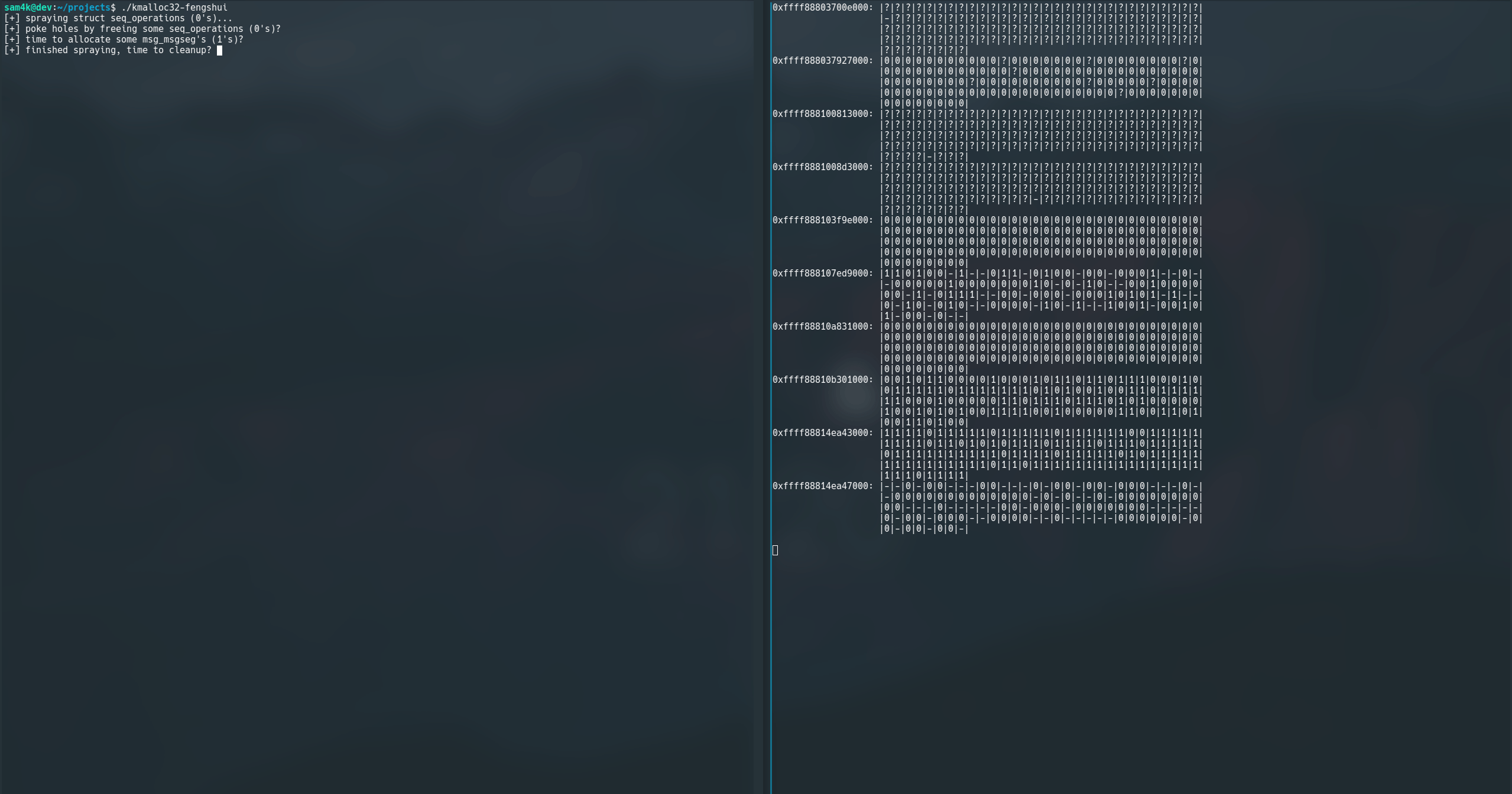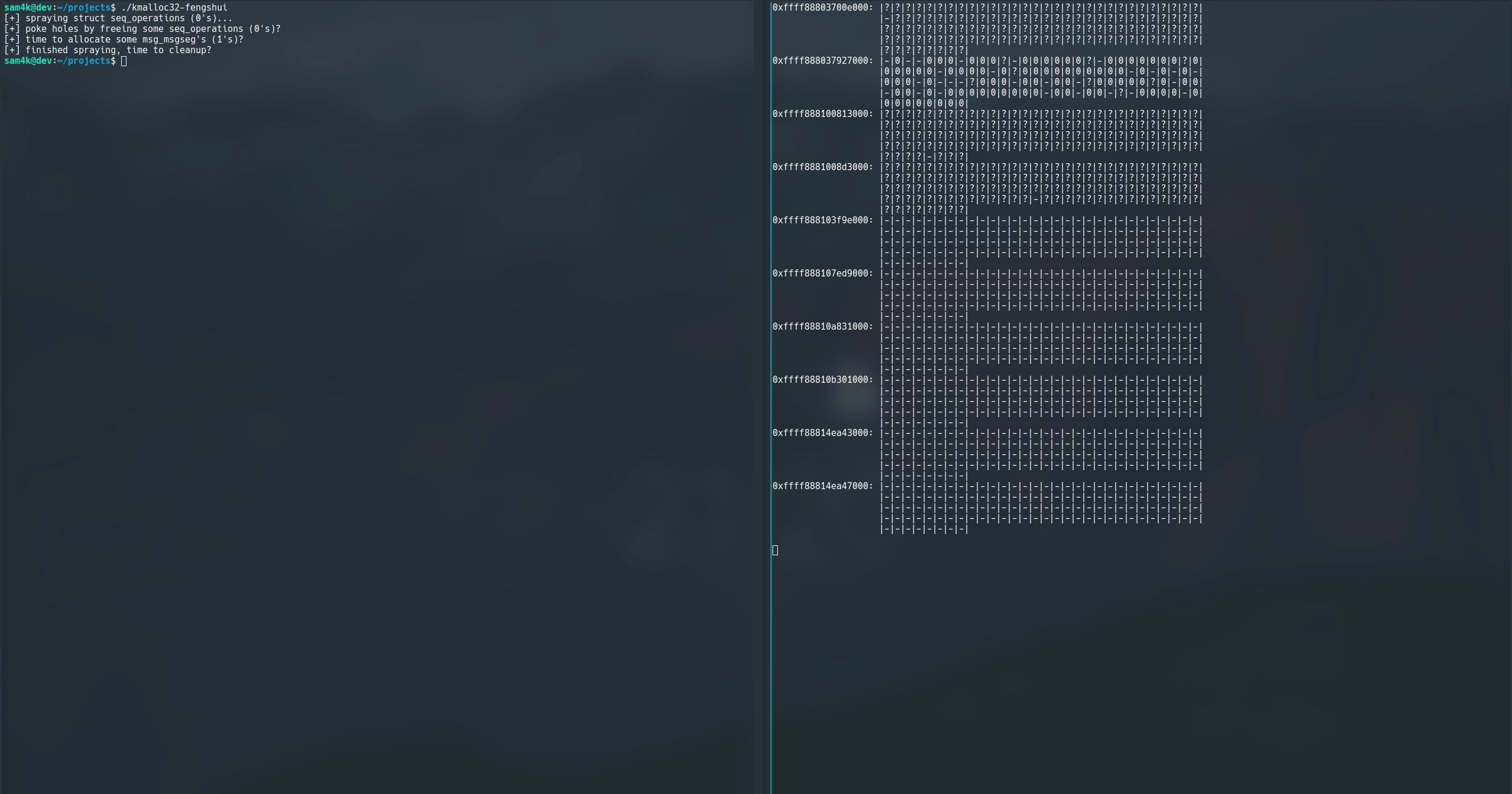
pls excuse the flickering… my fault for using linux
Let me explain what on earth is going on here. So, slxbtrace will basically hook and process calls to kmalloc() and kfree() and show you what’s where in a cache.
So far it’s pretty naive, when you run it, it has no knowledge of the cache state. However, once it starts catching kmalloc()’s it can build up an idea of where the slabs are (as they’re page aligned) and the objects in it.
Each known slab is visualised. We can see the slab address on the left, and then the objects in the slab as they’d sit in memory:
?meansslxbtracedoesn’t know the state of this object-represents a free objectxrepresents a misc allocations0...we can then tag specific allocations so they’re easy to visualise
So what’s going on in this demo?! Well I am tracking the state of the kmalloc-cg-32 cache with slxbtrace on the left, while I run a program will triggers a bunch of kmallocations on the right (kmalloc32-fengshui). This program:
- Triggers 800 allocations of
struct seq_operations, whose allocations are tracked as|0|, to fill up some slabs! - Free’s every other
struct seq_operationsafter the first 400, effectively trying to make some holes (denoted by|-|) in the slabs we just filled up - Next I allocate a bunch of
struct msg_msgsegs of the same size (denoted by|1|), trying to land them next to mystruct seq_operationsin memeory :D - Finally I cleanup everything and free it all :)
Right now this is just a very, very barebones poc and likely has some issues, but I thought it would be neat to share here as it demonstrates some of the stuff we’ve touched on.
I will absolutely share all this on my github though, once it’s in a shareable state, just in case anyone else is also interesting in playing around!
- https://www.kernel.org/doc/Documentation/ABI/testing/sysfs-kernel-slab
- https://sam4k.com/patching-instrumenting-debugging-linux-kernel-modules/#debugging
- not the final name, probably
Wrapping Up

Is this… did we… is it over? This one really turned into an absolute leviathan, but perhaps that’s just a testament to work that behind the kernel’s slab allocator!
In this post we covered an integral part to the kernels memory management subsystem: the slab allocator. Specifically, we looked at the SLUB implementation which is the de factor implementation on modern systems (bar embedded stuff).
We really lived up to the Linux internals namesake in this post, as we dived in and explored the SLUB allocator from all angles: the underpinning data structures, the API used by the rest of the kernel and then validated this all with some introspection.
Hopefully this provided a reasonably holistic insight into slab allocators, with opportunities for further reading/exploration readily available.
Also worth noting we kept things pretty shiny as we looked primarily at the latest (at the time of starting) kernel release, v6.0.6!
I was going to expand a bit on SLAB and SLOB, but to be honest we’re almost at 6000 words and it’s probably out of scope for my aims for this series, but just in case:
- SLAB (non-default since 14 years) was the prev default implementation and the tl;dr is it was more complex than SLUB and less friendly to modern multi-core systems [1]
- SLOB was introduced ~2005 and aimed at embedded devices, trying to think things compact as possible to make the most of less memory [2]
- https://www.kernel.org/doc/gorman/html/understand/understand011.html
- https://lwn.net/Articles/157944/
Next Time!

Well, to be honest, as far as “Memory Allocators” goes as a topic, we’ve done pretty well between our coverage on the buddy and slab allocators.
I’m not entirely sure there will be a next time for this mini series, I might hop back onto the virtual memory stuff and look into the lower level implementation there.
That said, if I were to explore the memory allocator space more I’d want to cover the security side of things: memory allocators in the context of exploit techniques and mitigations. If that’s something you’d be into, feel free to let me know :)
Otherwise: thanks for reading, and as always feel free to @me if you have any questions, suggestions or corrections :)
exit(0);