

I know you've all been waiting for it, that's right, we're going to be taking a dive into another exciting aspect of Linux internals: memory allocators!
Don't worry, I haven't forgotten about the virtual memory series, but today I thought we'd spice things up and shift our focus towards memory allocation in the Linux kernel. As always, I'll aim to lay the groundwork with a high level overview of things before gradually diving into some more detail.
In this first part (of many, no doubt), we'll cover the role of memory allocators within the Linux kernel at a high level to give some general context on the topic. We'll then take a look at the first of two types of allocator used by the kernel: the buddy (page) allocator.
We'll cover the high level implementation of the buddy allocator, with some code snippets from the kernel to complement this understanding, before diving into some more detail and wrapping things up by talking about some pros/cons of the buddy allocator.
Contents
0x01 So, Memory Allocators?
Alright, let's get stuck in! Like I mentioned, we'll start with the basics - what is a memory allocator? I could just say we're talking about a collection of code which looks to manage available memory, typically providing an API to allocate() and free() this memory.
But what does that mean? For a moment let's forget about the complexities of modern day memory management in OS's, with all the various interconnected components:
Picture a computer with some physical memory, running a Linux kernel and a lot of usermode processes (think of all the chrome tabs). Both the kernel and the various user processes require physical memory to store the various data behind the virtual mappings we covered in parts 2 & 3 of the virtual memory series.

Now picture the absolute chaos as processes are using the same physical memory addresses at the same time, clobbering each other's data, oh lord, even the kernel's data is getting overwritten? Is that chrome tab even using a physical address that exists?!
That is where the kernel's memory allocator comes in, acting as a gatekeeper of sorts for allocating memory when it is needed. It's job is to keep track of how much memory there is, what's free and what's in use.

Rather than every process for themselves, if something requires a chunk of memory to store stuff in, it asks the memory allocator - simple enough right?
0x02 The Buddy (Page) Allocator
Now we've got a high level understanding of memory allocators, let's take a look at how memory is managed and allocated in the Linux kernel.
While several implementations for memory allocation exist within the Linux kernel, they mainly work on top of the buddy allocator (aka page allocator), making it the fundamental memory allocator within the Linux kernel.
Page Primer
At this point, we should probably rewind and clarify what exactly a "page" is. As part of it's memory management approach, the Linux kernel (along with the CPU) divides virtual memory into "pages" which are PAGE_SIZE bytes of contiguous virtual memory.
Typically defined as 0x1000 bytes, or 4KB, pages are the common unit for managing memory in the Linux kernel. This is why you'll often see things in memory aligned on page boundaries, for example.
Anyway, while a fascinating topic, I'll not derail us too much! However this is definitely something I'll touch on in more detail in future posts, so don't worry :)
PAGE_SIZE, I'll assume a typical PAGE_SIZE of 0x1000.Buddy System Algorithm
Back to the topic at hand - we've covered where the "page" in page allocator comes from, what about the buddy part? Queue the buddy system algorithm (BSA) behind the buddy allocator, starting with the basics:
The buddy allocator tracks free chunks of physically contiguous memory via a freelist, free_area[MAX_ORDER], which is an array of struct free_area.
Each struct free_area in the freelist contains a doubly linked circular list (the struct list_head) pointing to the free chunks of memory.
...
struct free_area free_area[MAX_ORDER];
...
struct free_area {
struct list_head free_list;
unsigned long nr_free;
};Each struct free_area's linked list points to free, physically contiguous chunks of memory which are all the same size. The buddy allocator uses the index into the freelist, free_area[], to categorise the size of these free chunks of memory.
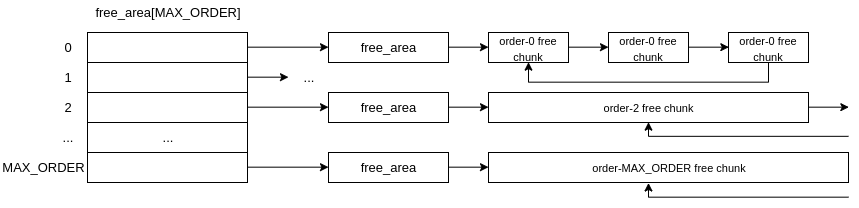
This index is called the "order" of the list, such that the size of the free chunks of memory pointed to are of size 2order * PAGE_SIZE, such that:
free_area[0]points to astruct free_areawhosefree_listcontains a list of free chunks of physically contiguous memory; each being20 * 0x1000bytes ==0x1000bytes AKA order-0 pages.free_area[1]points to astruct free_areawhosefree_listcontains a list of free chunks of physically contiguous memory; each being21 * 0x1000bytes ==0x2000bytes AKA order-1 pages.- ...
free_area[MAX_ORDER]-> points to astruct free_areawhosefree_listcontains a list of free chunks of physically contiguous memory; each being2MAX_ORDER * 0x1000bytes
Okay, what's this got to do with buddies Sam?! Good question! One that brings us onto how the buddy allocator (de)allocates all this free memory it tracks.
Being the buddy allocator, it provides an API for users to both allocate and free all these various sized, physically contiguous chunks of memory. If we want to call the equivalent of allocate(0x4000 bytes), what does this look like at a high level?
1) Determine what order-n page satisfies the size of our allocation, in maths world, they do this via log stuff: log2(alloc_size_in_pages), rounded up to the nearest int, will give us the appropriate order! Here, it's 2.
2) As the order is also the index into the freelist, we can check the corresponding free_area[2]->free_list to find a free chunk. If there is one, hoorah! We dequeue it from the list as it's no longer free and we can tell the caller about their newly acquired memory
3) However, if free_area[2]->free_list is empty, the buddy allocator will check the free_list of the next order up, in this case free_area[3]->free_list. If there's a free chunk, the allocator will then do the following:
- Remove the chunk from
free_area[3]->free_list - Half the chunk (as any order-n page is guaranteed to be exactly twice the size of the order-n-1 page, as well as being physically contiguous in memory), creating two buddies! (I told you we'd get round to it!)
- One chunk is returned to the caller who requested the allocation, while the other chunk is now migrated to the order-n-1 list,
free_area[2]->free_listin this case - On freeing, the allocator will check for physically adjacent, free chunks (buddies!) to remerge to higher orders if a
free_listhas too many freed chunks
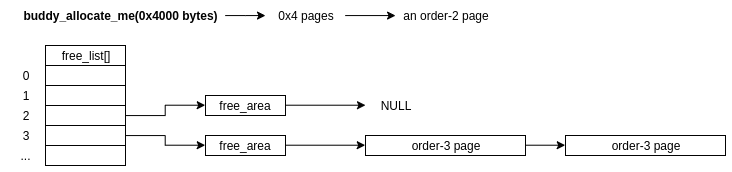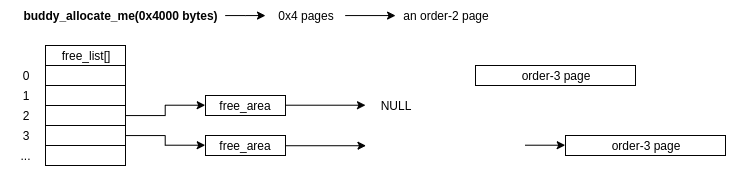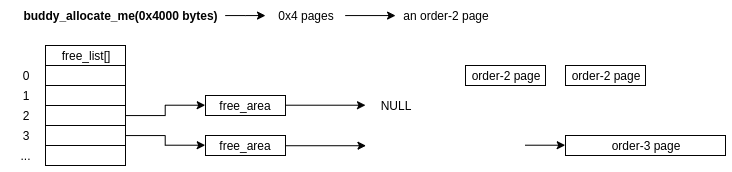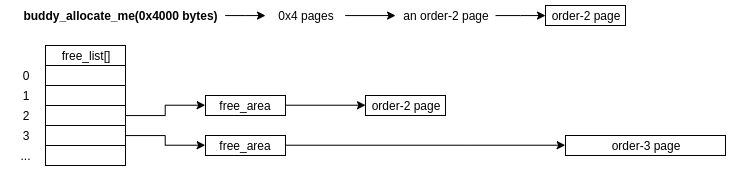
4) If free_area[3]->free_list is also empty, the allocater will continue to check the higher order freelists until either it finds a free chunk or the request fails (if there are no free chunks in any of the higher orders either).

And there we are, a grossly-simplified (as always) overview of the buddy allocator within the Linux kernel. Perhaps I made a mistake intertwining code snippets and kernel specifics with a simplified approach, but hopefully it all made sense!
Nodes, Zones & Memory Stuff
Okay, so we've covered things at a fairly high level, but I'd be remiss if I didn't clarify some of the specifics I glossed over in the last section, so buckle up.
First of all, in theme with our on going virtual memory series, let's clarify what exactly is being allocated here. We already know we're dealing with pages of memory, but where?
The buddy allocator is a virtual memory allocator, although it does so from the kernel region defined by __PAGE_OFFSET_BASE (aka lowmem aka physmap) which you'll recall[1] is a 1:1 virtual mapping of physical memory. Such that lowmem address x+1 will map to physical address y+1, x+2 to y+2, x+N to y+N etc; virtually contiguous memory from this region is guaranteed also to be physically contiguous too.
Keeping things relatively brief again, the Linux kernel organises physical memory into a tree-like hierarchy of nodes made up of zones made up of pages frames[2]:
- Nodes: these data structures, represented by
pg_data_t, are abstractions of actual physical hardware stuff, specifically a node represents a "bank" of physical memory - Zones: suffice to say nodes are made up of zones, represented by
struct zone, which represent ranges within memory - Page frames: zones are then page up of pages, represented by
struct page. Where a page describes a fixed-length (PAGE_SIZE) contiguous block of virtual memory, a page frame is a fixed-length contiguous block of physical memory that pages are mapped to
Expanding on free_area

Why am I burdening you with this knowledge? The answer is because not only did I leave out some details in the code snippet above by I straight up altered it (it was for your own good, I swear), so now I'm going to correct my wrongs by unveiling the truth:
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
struct zone {
...
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
...
}Okay, let's unpack this. The buddy allocator actually keeps track of multiple freelists, free_area[], specifically one per zone. We can see that here, as the freelist is actually a member of the struct zone which we touched on a moment ago.
Why? Err, good question. I won't delve into the nuances of NUMA/UMA systems and all that stuff but suffice to say when the buddy allocator is asked to allocate some memory, it may want to pick a zone from the node that is associated with the calling context (think "closest" node or most optimal).
Now that we have the full(ish) context, we can do a little bit of introspection and get some hands on using our ol' faithful procfs:
$ cat /proc/buddyinfo
----- zone info ------| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10
-------------------------------------------------------------------------------------------------
Node 0, zone DMA 0 0 0 0 0 0 0 0 1 1 2
Node 0, zone DMA32 11311 2358 1052 567 290 123 52 33 18 25 8
Node 0, zone Normal 5977 942 2093 1983 804 256 93 45 28 39 4 I've added some headers in (lines 2-3), but what we're seeing here is a row for each zone's buddy allocator freelist, free_area[MAX_ORDER]. The first column tells us the node and zone, then each column after that tells us how many free pages (nr_free) there are for each page order, starting from order 0 and moving to order MAX_ORDER. Neat, right?
Moving back to the deception, the doubly linked circular list we said pointed to all the free chunks? Well that's actually an array of linked circular lists: free_list[MIGRATE_TYPES]. Don't worry though, each list in the array still points to free chunks. Pages of different types, defined by the enum MIGRATE_TYPES, are just stored in seperate lists in this array.
Touching on struct page
Although I'm planning to cover this in much more detail in the virtual memory series, I feel like it's worth touching on this goliath as to fill in some gaps in our overview.
So we've already mentioned that each physical page (page frame) in the system has a struct page associated with it. This tracks various metadata and is instrumental to the kernel's memory management model.
Given that these represent physical pages, it might not come as a surprise to learn that the "free chunks" that free_area->free_list points to are actually references to page structs. We can see that here by poking around mm/page_alloc.c:
/*
* Do the hard work of removing an element from the buddy allocator.
* Call me with the zone->lock already held.
*/
static __always_inline struct page *
__rmqueue(struct zone *zone, unsigned int order, int migratetype,
unsigned int alloc_flags)Okay, whew, with that all cleared up, I think we have a reasonable overview of the buddy allocator within the Linux kernel! Hope you're still with me as we're not done yet!
- https://sam4k.com/linternals-virtual-memory-part-3/
- More on the topic here https://www.kernel.org/doc/gorman/html/understand/understand005.html
Using The Buddy Allocator

I figured I should get into the habit of promoting some kernel development hijinx and explore some of the APIs for the topics we discuss where relevant.
Let's dive in then and highlight some of the API exposed to kernel developers for use in modules & device drivers. All defs can be found in /include/linux/gfp.h:
alloc_pages(gfp_mask, order): Allocate 2order pages (one physically contiguous chunk from the order N freelist) and return astruct pageaddressalloc_page(gfp_mask): macro foralloc_pages(gfp_mask, 0)__get_free_pages(gfp_mask, order)and__get_free_page(gfp_mask)mirror the above functions, except they return a virtual address to the allocation as opposed to astruct page- For freeing options include:
__free_page(struct page *page),__free_pages(struct page *page, order)andfree_page(void *addr) - Plenty more to see if you take a browse of
/include/linux/gfp.h
Most of that should be fairly familiar at this point, except the gfp_mask, which we haven't covered. The gfp_mask is a set of GFP (Get Free Page) flags which lets us configure the behaviour of the allocator and are used across the kernels memory management stuff.
The inline documentation[1] already does a good job at covering the different flags, so I won't rehash that here. My experience has mainly seen GFP_KERNEL, GFP_KERNEL_ACCOUNT[2], GFP_ATOMIC.
Despite a flexible API for different allocation use cases and requirements, they all ultimately call the real MVP, __alloc_pages():
/*
* This is the 'heart' of the zoned buddy allocator.
*/
struct page *__alloc_pages(gfp_t gfp, unsigned int order, int preferred_nid,
nodemask_t *nodemask)We've already covered a lot of ground in this post, so I'll leave it as an exercise to the reader to take a look at this function to see what we've covered so far in actual code :)
I'll also use this as an opportunity to plug my long neglected repo (but I plan to push some demos for Linternals posts up too, maybe), "lmb" aka Linux Misc driver Boilerplate; a very lightweight kernel module boilerplate for bootstraping kernel fun.
 sam4k
sam4k- https://elixir.bootlin.com/linux/v5.18.3/source/include/linux/gfp.h#L271
- @poppop7331 and @vnik5287 recently did a cool blog post covering modern heap exploitation, including the implications of
GFP_KERNEL_ACCOUNTin recent kernel versions :)
Pros & Cons

Before we wrap up, and to give some context on the next section, let's take what we've learned about the buddy allocator and highlight some of it's pros and cons.
First of all, due to the nature of the buddy system algorithm behind things, the buddy allocator is fast to (de)allocate memory. Furthermore, being able to split and remerge chunks on the go, there is little external fragmentation (this is where there's enough free memory to serve a request, just not in one contiguous chunk).
There's also other perf benefits, that we won't dive into here, to providing physically contiguous memory and guaranteeing cache aligned memory blocks.
The main downside here is the internal fragmentation, where the chunk of memory allocated is bigger than necessary, leaving a portion of it unused. Due to the fixed sizes, determined by 2order pages, if a request falls just too big for the previous order, we're gonna have a great deal of space wasted. Not to mention the smallest allocation is 1 page.
tl;dr: fast, contiguous allocations, low external fragmentation, bad internal fragmentation
Wrapping Up
Memory allocation and management is an extremely complex topic with a lot of nuance and complexity which, as we saw, extends down to the hardware level.
Hopefully this has been a useful primer on one of the fundamentals to kernel memory allocation, the buddy allocator:
- We covered the role of memory allocators briefly, before learning that the buddy allocator acts as a fundamental memory allocation mechanism within the Linux kernel
- We learned at a high level about the buddy system algorithm behind the buddy allocator, with some peaks into the actual kernel code from the mm system
- Finally we pieced together our understanding with some extras on how memory is managed by the kernel, it's API and the pros/cons of the buddy allocator
Next Time!

The fun doesn't end here, don't you worry! We've just scratched the surface. I hope you're ready to expand your repertoire of acronyms cos next time we'll be exploring the wonderful world of slab allocators: SLAB, SLUB & SLOB.
Sitting above the buddy allocator, the slab allocator is another fundamental aspect of memory allocation and management in the Linux kernel, addressing the internal fragmentation problems of the buddy allocator - but that's for next time!
Thanks for reading, and as always feel free to @me if you have any questions, suggestions or corrections :)
exit(0);