

Alright, we really made it to part 3 eh? Not bad! Before we dive straight in, let's quickly go over what we covered in the last part on the user virtual address space:
- Very brief overview, with some examples, of using
procfsfor introspection - The various mappings that make up a typical user virtual address space
- Which syscalls userspace programs make use of to set up their virtual address space
- Finally tying up some extras with how threading & ASLR fit into this picture
This time we'll be pivoting our attention towards the omnipresent kernel virtual address space, where all the true power resides, so let's get stuck into chapter 5!

Contents
0x05 Kernel Virtual Address Space
Casting our minds back to part 1, we'll recall that:
- Each process has it's own, sandboxed virtual address space (VAS)
- The VAS is vast, spanning all addressable memory
- This VAS is split between the User VAS & Kernel VAS[1]
As we touched on in part 1, and more so in part 2, to even set up it's user VAS a process needs the kernel to carry out a series of syscalls (brk(), mmap(), execve() etc.)[2].
This is because our userspace is running in usermode (i.e. unprivileged code execution) and only the kernel is able to carry out important, system-altering stuff (right??).
So if we're in usermode and we need the kernel to do something, like mmap() some memory for us, then we need to ask the kernel to do it for us and we do this via syscalls.
Essentially, a syscall acts as a interface between usermode and kernelmode (privileged code execution), only allowing a couple of things to cross over from usermode: the syscall number & it's arguments.
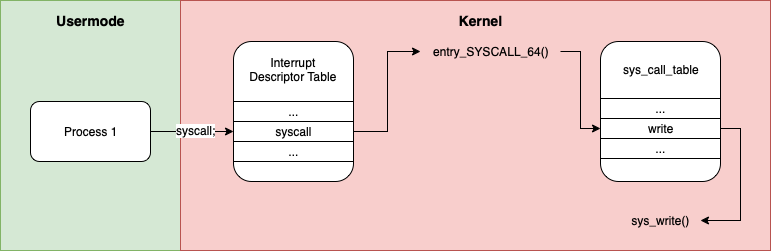
This way the kernel can look up the function corresponding to the syscall number, sanitise the arguments (the userspace has no power here after all) and if everything looks good, it can carry out the privileged work, return to the syscall handler which can transition back to usermode, only allowing one thing to cross over: the result of the syscall.

This is all a roundabout way of broaching the question: we understand the userspace, but when we make a syscall[3], what is it running and how does it know where to find it?
And THAT is where the kernel virtual address space comes in. Got there eventually, right?
- The VAS is often so vast (e.g. on 64-bit systems), that rather than splitting the entire address space an upper & lower portion are assigned to the kernel and user respectively, with the majority in between being non-canonical/unused addresses.
- We touched more on syscalls back in part 1, "User-mode & Kernel-mode"
- In the future I might dedicate a full post (or 3 lol) to the syscall interface, so if that's something you'd be into, feel free to poke me on Twitter
One Mapping To Rule Them All
Okay, so I know we're all eager to dig around the kernel VAS, but it's worth noting a fairly fundamental difference here: while each process has it's own unique user VAS, they all share the same kernel VAS.
Huh? What exactly does this mean? Well, to put simply, all our processes are interacting with the same kernel, so each process's kernel VAS maps to the same physical memory.
As such, any changes within the kernel will be reflected across all processes. It's important to note, and we'll cover the why in more detail later, when we're in usermode we have no read/write access to this kernel virtual address space.
This is an extremely high-level overview of the topic and the actual details will vary based on architecture & security mitigations, but for now just remember that all processes share the same kernel VAS.
Kernel Virtual Memory Map

Unfortunately things aren't going to be as tidy and straightforward as our tour of the user virtual address space. The contents of kernelspace varies depending on architecture and unfortunately there isn't easy-to-visualise introspection via procfs.
As I've mentioned before in Linternals, I'll be focusing on x86_64 when architecture specifics come into play. So although we don't have procfs, we do have kernel docs!
Documentation/x86/x86_64/mm.txt, specifically, provides a /proc/self/maps-esque breakdown of the x86_64 virtual memory map, including both UVAS & KVAS; which is perfect for us[1]:
========================================================================================================================
Start addr | Offset | End addr | Size | VM area description
========================================================================================================================
| | | |
0000000000000000 | 0 | 00007fffffffffff | 128 TB | user-space virtual memory, different per mm
__________________|____________|__________________|_________|___________________________________________________________
| | | |
0000800000000000 | +128 TB | ffff7fffffffffff | ~16M TB | ... huge, almost 64 bits wide hole of non-canonical
| | | | virtual memory addresses up to the -128 TB
| | | | starting offset of kernel mappings.
__________________|____________|__________________|_________|___________________________________________________________
|
| Kernel-space virtual memory, shared between all processes:
____________________________________________________________|___________________________________________________________
| | | |
ffff800000000000 | -128 TB | ffff87ffffffffff | 8 TB | ... guard hole, also reserved for hypervisor
ffff880000000000 | -120 TB | ffff887fffffffff | 0.5 TB | LDT remap for PTI
ffff888000000000 | -119.5 TB | ffffc87fffffffff | 64 TB | direct mapping of all physical memory (page_offset_base)
ffffc88000000000 | -55.5 TB | ffffc8ffffffffff | 0.5 TB | ... unused hole
ffffc90000000000 | -55 TB | ffffe8ffffffffff | 32 TB | vmalloc/ioremap space (vmalloc_base)
ffffe90000000000 | -23 TB | ffffe9ffffffffff | 1 TB | ... unused hole
ffffea0000000000 | -22 TB | ffffeaffffffffff | 1 TB | virtual memory map (vmemmap_base)
ffffeb0000000000 | -21 TB | ffffebffffffffff | 1 TB | ... unused hole
ffffec0000000000 | -20 TB | fffffbffffffffff | 16 TB | KASAN shadow memory
__________________|____________|__________________|_________|____________________________________________________________
|
| Identical layout to the 56-bit one from here on:
____________________________________________________________|____________________________________________________________
| | | |
fffffc0000000000 | -4 TB | fffffdffffffffff | 2 TB | ... unused hole
| | | | vaddr_end for KASLR
fffffe0000000000 | -2 TB | fffffe7fffffffff | 0.5 TB | cpu_entry_area mapping
fffffe8000000000 | -1.5 TB | fffffeffffffffff | 0.5 TB | ... unused hole
ffffff0000000000 | -1 TB | ffffff7fffffffff | 0.5 TB | %esp fixup stacks
ffffff8000000000 | -512 GB | ffffffeeffffffff | 444 GB | ... unused hole
ffffffef00000000 | -68 GB | fffffffeffffffff | 64 GB | EFI region mapping space
ffffffff00000000 | -4 GB | ffffffff7fffffff | 2 GB | ... unused hole
ffffffff80000000 | -2 GB | ffffffff9fffffff | 512 MB | kernel text mapping, mapped to physical address 0
ffffffff80000000 |-2048 MB | | |
ffffffffa0000000 |-1536 MB | fffffffffeffffff | 1520 MB | module mapping space
ffffffffff000000 | -16 MB | | |
FIXADDR_START | ~-11 MB | ffffffffff5fffff | ~0.5 MB | kernel-internal fixmap range, variable size and offset
ffffffffff600000 | -10 MB | ffffffffff600fff | 4 kB | legacy vsyscall ABI
ffffffffffe00000 | -2 MB | ffffffffffffffff | 2 MB | ... unused hole
__________________|____________|__________________|_________|___________________________________________________________Line 5: We've touched on this previously, the lower portion of our virtual addresses space[2] makes up the userspace. Size varies per architecture.
Line 8: Remember how the virtual address spans every possible address, which is A LOT? As a result, the majority of this is non-canonical, unused space.
Line 16: My understanding is the guard hole initially existed to prevent accidental accesses to the non-canonical region (which would cause trouble), nowadays the space is also used to load hypervisors into.
Line 17: This will make more sense after we cover virtual memory implementation, but the per-process Local Descriptor Table describes private memory descriptor segments[3].
When Page Table Isolation (a mitigation, see below) is enabled, the LDT is mapped to this kernelspace region to mitigate the contents being accessed by attackers.
Line 18: Defined by __PAGE_OFFSET_BASE, the "physmap" (aka lowmem) can be seen as the start of the kernelspace proper. It is used as a 1:1 mapping of physical memory.
To recap, virtual addresses can be mapped to somewhere in physical memory. E.g. if we load a library into our virtual address space, the virtual address it's been mapped to actual points to some physical memory where that's been loaded to.
In another process, with it's own virtual address space, that same virtual address may be mapped to a completely different physical memory address.
Unlike typical virtual addresses (we'll touch on how they're translated), addresses in the physmap region are called kernel logical addresses. Any given kernel logical address is a fixed offset (PAGE_OFFSET) from the corresponding physical address.
E.g. PAGE_OFFSET == physical address 0x00, PAGE_OFFSET+0x01 == physical address 0x01 etc. etc.

Line 19: Not much more to say about these, other than it's an unused region!
Line 20[4]: Defined by VMALLOC_START and VMALLOC_END, this virtual memory region is reserved for non-contiguous physical memory allocations via the vmalloc() family of kernel functions (aka highmem region).
This is similar to how we initially understood virtual memory, where two contiguous virtual addresses in the vmalloc region may not necessarily map to two contiguous physical memory addresses (unlike physmap which we just covered).
This region is also used by ioremap(), which doesn't actually allocate physical memory like vmalloc() but instead allows you to map a specified physical address range. E.g. allocating virtual memory to map I/O stuff for your GPU.
To oversimplify, though we'll expand on later, as this region isn't simply physical address = logical address - PAGE_OFFSET, there's more overhead behind the scenes using vmalloc() which uses virtual addressing than say kmalloc(), which returns addresses from the physmap region.
Line 21: Another unused memory region!
Line 22[5]: Defined by VMEMMAP_START, this region is used by the SPARSEMEM memory model in Linux to map the vmemmap. This is a global array, in virtual memory, that indexes all the chunks (pages) of memory currently tracked by the kernel.
Line 23: Aaand another unused memory region!
Line 24[6]: The Kernel Address Sanitiser (KASAN) is a dynamic memory error detector, used for finding use-after-free and out-of-bounds bugs. When enabled, CONFIG_KASAN=y, this region is used as shadow memory by KASAN.
This basically means KASAN uses this shadow memory to track memory state, which it can then compare later on with the original memory to make sure there's no shenanigans or undefined behaviour going on.
Line 30: You get the idea, unused.
Line 31: Straight from the comments, defined by CPU_ENTRY_AREA_BASE, "cpu_entry_area is a percpu region that contains things needed by the CPU and early entry/exit code"[7]. The struct cpu_entry_area can share more insights on its role.
CPU_ENTRY_AREA_BASE is also used by vaddr_end, which along with vaddr_start marks the virtual address range for Kernel Address Space Layout Randomization (KASLR).
Line 32: Yep, unused region.

Line 33: Enabled with CONFIG_X86_ESPFIX64=y, this region is used to, and I honestly don't blame you if this makes no sense yet, fix issues with returning from kernelspace to userspace when using a 16-bit stack...
Again, the comments can be insightful here, so feel free to take a gander at the implementation in arch/x86/kernel/espfix_64.c.
Line 34: Another unused region.
Line 35: Defined by EFI_VA_START, this region unsurprinsgly is used for EFI related stuff. This is the same Extensible Firmware Interface we touch on in the (currently unfinished, oops) Linternals series on The (Modern) Boot Process.
Line 36: More unused memory.
Line 37: This region is used as a 1:1 mapping of the kernel's text section, defined by __START_KERNEL_map. As we mentioned before, the kernel image is formatted like any other ELF, so has the same sections.
This is where we find all the functions in your kernel image, which is handy for debugging! In this instance, if we're debugging an x86_64 target we can get a rough idea of what we're looking atjust from the address.
If we see the 0xffffffff8....... then we know we're looking at the text section!
Line 38: Any dynamically loaded (think insmod) modules are mapped into this region, which sits just other the kernel text mapping as we can see in the definition:
#define MODULES_VADDR (__START_KERNEL_map + KERNEL_IMAGE_SIZE)Line 39: Defined by FIXADDR_START, this region is used for "fix-mapped" addresses. These are special virtual addresses which are set/used at compile-time, but are mapped to physical physical memory at boot.
The fix_to_virt() family of functions are used to work with these special addresses.
Line 40: We actually snuck this in to our last part! To recap, this region is:
a legacy mapping that actually provided an executable mapping of kernel code for specific syscalls that didn't require elevated privileges and hence the whole user -> kernel mode context switch. Suffice to say it's defunct now, and calls to vsyscall table still work for compatibility, but now actually trap and act as a normal syscall
Line 41: Our final unused memory region!
- The eagle-eyed will note there's a couple of diagrams in mm.txt, one for 4-level page tables and one for 5-level. We'll touch on what this means in the next section, for now just know that 4-level is more common atm
- Specifically, depending on the arch, the most significant N bits are always 0 for userspace and 1 for kernelspace; on
x86_64this is bits48-63. This leaves 248 bits of addressing for both userspace and kernelspace (128TB) - https://en-academic.com/dic.nsf/enwiki/1553430
- https://www.oreilly.com/library/view/linux-device-drivers/0596000081/ch07s04.html
- https://blogs.oracle.com/linux/post/minimizing-struct-page-overhead
- https://www.kernel.org/doc/html/latest/dev-tools/kasan.html
- https://elixir.bootlin.com/linux/v5.17.5/source/arch/x86/include/asm/cpu_entry_area.h#L90
Wrapping Up

We did it! We've covered all the regions described in the kernel x86_64 4-page (we'll get on that in the next section) virtual memory map!
Hopefully there was enough detail here to provide some interesting context, but not so much that you might have well been reading the source. For the more curious, we'll be focusing more on implementation details in the next part.
Digging Deeper
If you're interested in exploring some of these concepts yourself, don't be scared away by the source! Diving into some of the #define's and symbols we've mentioned so far and rooting around can be a good way to dive in. bootlin's Elixr Cross Referencer is easy to use and you can jump about the source in your browser.
Additionally, playing around with drgn (live kernel introspection), gdb (we covered getting setup in this post) and coding is a fun way to get stuck in and explore these memory topics.
Next Time!
After 3 parts, we've laid a solid foundation for our understanding of what virtual memory is and the role it plays in Linux; both in the userspace and kernelspace.
Armed with this knowledge, we're in a prime position to begin digging a little deeper and getting into some real Linternals as we take a look at how things are actually implemented.
Next time we'll begin to take a look, at both a operating system and hardware level, how this all works. I'm not going to pretend I know how many parts that'll take!
Down the line I would also like to close this topic by bringing everything we've learnt together by covering some exploitation techniques and mitigations RE virtual memory.
Thanks for reading!
exit(0);