Exploring Linux's New Random Kmalloc Caches

In this post we’re going to be taking a look at the state of contemporary kernel heap exploitation and how the new opt-in hardening feature added in the 6.6 Linux kernel, RANDOM_KMALLOC_CACHES, looks to address that.
To provide some context to the problems RANDOM_KMALLOC_CACHES tries to address, we’ll spend a bit of time covering the current heap exploitation meta. This actually ended up being reasonably in-depth (oops) and touches on general approaches to exploitation as well as current mitigations and techniques such as heap feng shui, cache reuse attacks, FUSE and making use of elastic objects.
Armed with that information we’ll then explore the new patch in detail, discuss how it addresses heap exploitation and have a bit of fun speculating how the meta might shift as a result of this.
As this post is focusing on kernel heap exploitation, I’ll be assuming some prerequisite knowledge around topics like kernel memory allocators (luckily for you I’ve written about this already in some detail as part of Linternals, here).
Contents
- Current Heap Exploitation Meta
- Introducing Random Kmalloc Caches
- Diving Into The Implementation
- What’s The New Meta?
- Wrapping Up
Current Heap Exploitation Meta

Alright, before we dive into the juicy details lets quickly touch on the current state of heap exploitation to help us understand why this patch was added and how it effects things!
Heap corruption is one of the more common types of bugs found in the kernel today (think use-after-free, heap overflow etc.). When we talk about heap corruption in the Linux kernel, we’re referring to memory dynamically allocated via the slab allocator (e.g. [kmalloc()](https://elixir.bootlin.com/linux/v6.6/source/include/linux/slab.h#L590)) or directly via the page allocator (e.g. [alloc_pages()](https://elixir.bootlin.com/linux/v6.6/source/include/linux/gfp.h#L269)).
The fundamental goal of exploitation is to leverage our heap corruption to gain more control over the system, typically to elevate our privileges or at least get closer to being able to do so.
In reality, these heap corruptions can come in all shapes and sizes. The objects we’re able to use-after-free can come from different caches, there may be a race involved, there may be fields which need to be specific values etc. Similarly our overflows can also have any number of constraints which impact our approach to leverage the corruption.
However, there exist a number of generic techniques for heap exploitation, which help cut down on the time needed to go from heap corruption to working exploit. As we know, security is a cat and mouse game, so these techniques are continually adapting to keep up with new mitigations.
From a defenders perspective, in an ideal world we would mitigate heap corruption bugs entirely. Failing that, we can make it as hard as possible for attackers to leverage any heap corruption bugs they do find. Responding to the generic techniques used by attackers is a good way to go about this, forcing each bug to require a bespoke approach to exploit.
Approaching Heap Exploitation

Okay with the exposition out of the way, lets talk a bit about how we might go about exploiting a heap corruption in the kernel nowadays. I’m going to (try) keep things fairly high level, with a focus on the slab allocator side of things due to the topics context.
So first things first we want to make sure we understand the bug itself: how do we reach it, what kernel configurations or capabilities do we require? What is the nature of the corruption, is it a use-after-free? What are the limitations around triggering the bug? What data structures are effected, what are the risks of a kernel panic?
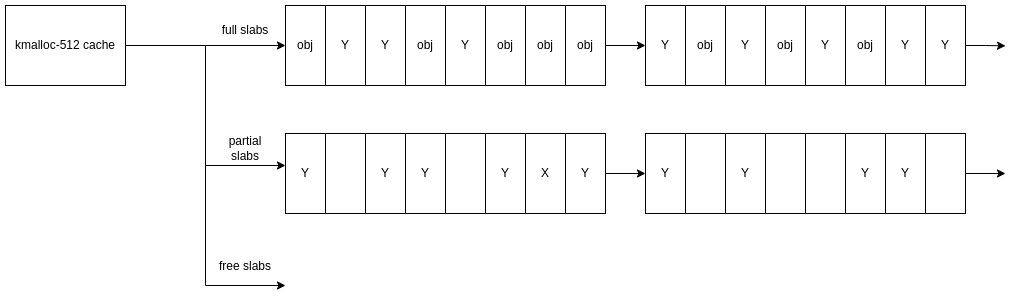
Then we want to get into the specifics of the heap corruption itself. How are the affected objects allocated? Is it via the slab allocator or the page allocator? For slab allocations, we’re interested in what cache the object is allocated to, so we can infer what other objects share the same cache and can potentially be corrupted.
There are several factors to consider at the moment when determining what cache our object will end up in:
- The API used will tell us if its allocated into a general purpose cache with other similar sized objects (
kmalloc(),kzalloc(),kcalloc()etc.) or private cache ([kmem_cache_alloc()](https://elixir.bootlin.com/linux/v6.6/source/include/linux/slab.h#L499)) with slabs containing only objects of that type. - The GFP (Get Free Page) flags used can tell us which of the general purpose cache types the object is allocated. By default, allocations will go to the standard general purpose caches,
kmalloc-x, where x is the “bucket size”. The other common case isGFP_KERNEL_ACCOUNT, typically used for untrusted allocations[1], will put objects in an accounted cache, namedkmalloc-cg-x. - The size of the object will determine, for general purpose caches, which “bucket size” the object will end up in. The
xinkmalloc-xdenotes the fixed size in bytes allocated to each object in the cache’s slabs. Objects will be allocated into the smallest general purpose cache is can fit into.
Now we’ve built up an understanding of the bug and how it’s allocated, it’s time to think about how we want to use our corruption. By knowing what cache our object is in, we know what other objects can or can’t be allocated into the same slab.
The general goal here is to find a viable object to corrupt. We can use our understanding of how the slab allocator works in order to shape the layout of memory to make this more reliable, or to make otherwise incorruptible objects corruptible.
Current Mitigations

However, before we get ahead of ourselves, we first have to consider any mitigations that might impact our ability to exploit our bug on modern systems. This won’t be an exhaustive list, but will help provide some context on the current meta:
[CONFIG_SLAB_FREELIST_HARDENED](https://cateee.net/lkddb/web-lkddb/SLAB_FREELIST_HARDENED.html)adds checks to protect slab metadata, such as the freelist pointers stored in free objects within a SLUB slab and checks for double-frees.[CONFIG_SLAB_FREELIST_RANDOM](https://cateee.net/lkddb/web-lkddb/SLAB_FREELIST_RANDOM.html)randomises the freelist order when a new cache slab is allocated, such that an attacker can’t infer the order objects within that slab will be filled. The aim to reduce the knowledge & control attackers have over heap state.[CONFIG_STATIC_USERMODEHELPER](https://cateee.net/lkddb/web-lkddb/STATIC_USERMODEHELPER.html)mitigates a popular technique for leveraging heap corruption, which we’ll touch on in the next section.- Slab merging, enabled via
slub_mergebootarg orCONFIG_SLAB_MERGE_DEFAULT=y, allows slab caches to be merged for performance. As you can imagine, this is nice for attackers as it opens up our options for corruption. - Some others, which are less commonly enabled afaik, or out of scope include
[CONFIG_SHUFFLE_PAGE_ALLOCATOR](https://cateee.net/lkddb/web-lkddb/SHUFFLE_PAGE_ALLOCATOR.html),[CONFIG_CFI_CLANG](https://cateee.net/lkddb/web-lkddb/CFI_CLANG.html),init_on_alloc/[CONFIG_INIT_ON_ALLOC_DEFAULT_ON=y](https://cateee.net/lkddb/web-lkddb/INIT_ON_ALLOC_DEFAULT_ON.html)&init_on_free/[CONFIG_INIT_ON_FREE_DEFAULT_ON=y](https://cateee.net/lkddb/web-lkddb/INIT_ON_FREE_DEFAULT_ON.html).
Generic Techniques

Okay, now we’re ready to starting pwning the heap. We understand our bug, the allocation context and the kind of mitigations we’re dealing with. Let’s explore some contemporary techniques used to get around this mitigation and exploit heap corruptions bugs!
Basic Heap Feng Shui
A fundamental aspect of heap corruption is the ability to shape the heap, commonly referred to as “heap feng shui”. We can use our understanding of how the allocator works and the mitigations in place to try get things where we want them in the heap.
Lets use a generic heap overflow to demonstrate this. We can overflow object x and we want to corrupt object y. They’re in the same generic cache, so our goal is to land y adjacent to x in the same slab.
We want to consider how active the cache is (aka is it cache noise) and up-time, as this will give us an idea of the cache slab state. On a typical workload with a fairly used cache size, we can assume there are likely to be several partially filled slabs; this is our starting state.
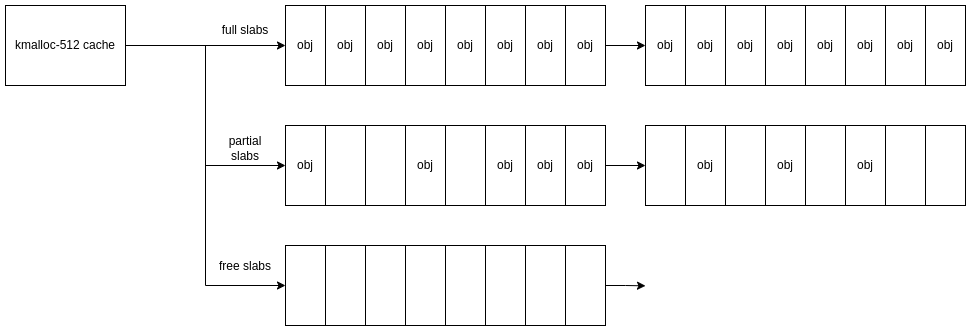
A basic heap feng shui approach would be to first allocate a number of object y to fill up the holes in the partial slabs:
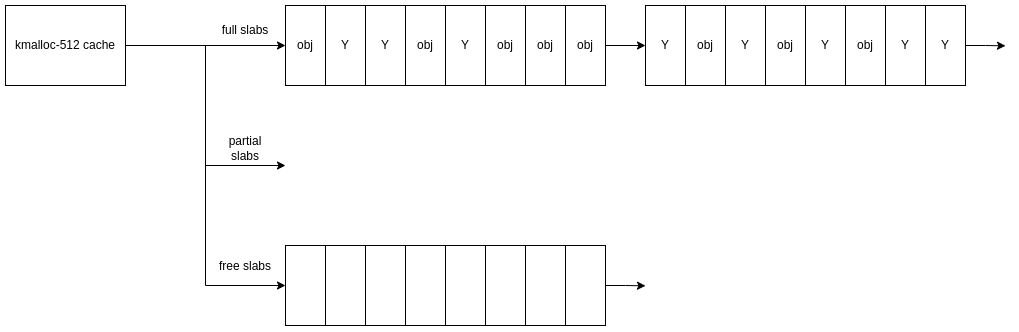
Then, we allocate several slabs worth of object y which we can assume is to trigger new slabs to be allocated, hopefully filled with object y:
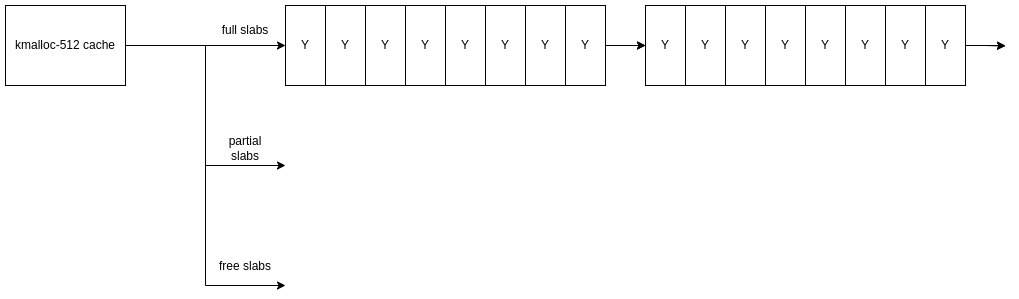
Then, from the second batch of allocations into new slabs, we would free every other allocation to try and create holes in the new slabs:
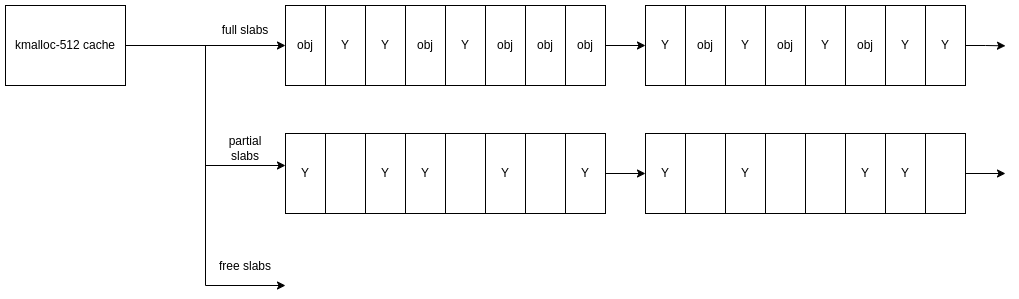
We would then allocate our vulnerable object x in the hopes we have increased our chances that it will be allocated into one of the wholes we just created:
Cache Reuse/Overflow Attacks
Remember earlier we mentioned how there are different types of general purpose caches and even private caches, all with their own slabs? What if our vulnerable object is in one cache and we found an object we really, really wanted to corrupt in another cache?
If we recall our memory allocator fundamentals[2], we know that the page allocator is the fundamental memory allocator for the Linux kernel, sitting above it is the slab allocator. So the slab allocator makes use of the page allocator, this includes for the allocation of the chunks of memory used as slabs (to hold cache objects). Are you still with me?
So when all the objects in a slab are freed, the slab itself may in turn be freed back to the page allocator, ready to be reallocated. Can you see where this is going?

If we have a UAF on an object in a private cache slab, if that slab is then freed and reallocated as a general purpose cache, suddenly our UAF’d memory is pointing to general purpose objects! Our options for corruption have suddenly expanded!
This kind of technique is known as a “cache reuse” attack and has been documented previously in more detail[3]. By using a similar approach of manipulating the underlying page layout, “cache overflow” attacks are possible too, where you align to slabs from separate caches adjacent to one another in physical memory, which has been used in some great CTF writeups[4].
Elastic Objects
Another cornerstone of contemporary heap exploitation is the use of “elastic objects”[6]. These are essential structures that have a dynamic size, typically a length field will describe the size of a buffer within the same struct.
Sounds pretty straight forward, right? Why is this relevant? Well, we’ve spoken about the bespoke nature of heap corruption vulnerabilities, and the variety of cache types and sizes.
Elastic objects can provide generic techniques to exploiting these vulnerabilities, as objects that can be corrupted across a variety of cache sizes due to their elastic nature. By generalising the object being corrupted, a lot of time can be spent mining for objects that are corruptible for a certain cache size and then developing a bespoke technique for using that specific corruption to elevate privileges (which can be quite time consuming!).
A popular elastic object used on contemporary heap corruption is [struct msg_msg](https://elixir.bootlin.com/linux/v6.6/source/include/linux/msg.h#L9), which can be used to leverage an out-of-bounds heap write into arbitrary read/write[5]:
/* one msg_msg structure for each message */
struct msg_msg {
struct list_head m_list;
long m_type;
size_t m_ts; /* message text size */
struct msg_msgseg *next;
void *security;
/* the actual message follows immediately */
};
include/linux/msg.h (v6.6)
FUSE

Seeing as we’re going all out on the exploitation techniques here, I might as well throw in a quick shoutout to FUSE as well, which is commonly used in kernel exploitation.
Filesystem in Userspace is “is an interface for userspace programs to export a filesystem to the Linux kernel.”[7], enabled via [CONFIG_FUSE_FS](https://cateee.net/lkddb/web-lkddb/FUSE_FS.html)=y. Essentially it allows, often unprivileged, users to define their own filesystems.
Normally, mounting filesystems is a privileged action and actually defining a filesystem would require you to write kernel code. With FUSE, we can do away with this. By defining the read operations in our FUSE FS, we’re able to define what happens when kernel tries to read one our FUSE files, which includes sleeping…
This gives us the ability to arbitrarily block kernel threads that try to read files in our FUSE FS (essentially accessing to user virtual addresses we can control, as we can map in one of our FUSE files and pass that over to the kernel).
So what does this have to do with kernel exploitation? Well, as we mentioned previously, a key part of heap exploitation is finding interesting objects to corrupt or control the layout of memory. Ideally we want to be able to allocate and free these on demand, if they’re immediately freed there’s not too much we can do with them … right?
Perhaps! This is where FUSE comes in: if we have a scenario where an object we really, really want to corrupt is allocated and freed within the same system call, we may be able to keep it in memory if there’s a userspace access we can block on between the allocation and free! You can find more on this, plus some examples, from this 2018 Duasynt blog post.
- https://www.kernel.org/doc/Documentation/core-api/memory-allocation.rst
- https://sam4k.com/linternals-memory-allocators-part-1/
- https://duasynt.com/blog/linux-kernel-heap-feng-shui-2022
- https://www.willsroot.io/2022/08/reviving-exploits-against-cred-struct.html
- https://www.willsroot.io/2021/08/corctf-2021-fire-of-salvation-writeup.html
- the earliest mention i’m aware of in an kernel xdev context is from the 2020 paper, “A Systematic Study of Elastic Objects in Kernel Exploitation”, could we be wrong tho
- https://github.com/libfuse/libfuse
- https://duasynt.com/blog/linux-kernel-heap-spray
Introducing Random Kmalloc Caches

Well, that was quite the background read (sorry not sorry), but we’re hopefully in a good position to dive into this new mitigation: Random kmalloc caches[1].
This mitigation effects the generic slab cache implementation. Previously, there was a single generic slab cache for each size “step”: kmalloc-32, kmalloc-64, kmalloc-128 etc. Such that an 40 byte object, allocated via kmalloc(), with the correct GFP flags, is always going to end up in the kmalloc-64 cache. Straightforward right?
CONFIG_RANDOM_KMALLOC_CACHES=y introduces multiple generic slab caches for each size, 16 by default (named kmalloc-rnd-01-32, kmalloc-rnd-02-32 etc.). When an object allocated via kmalloc() it is allocated to one of these 16 caches “randomly”, depending on the callsite for the kmalloc() and a per-boot seed.
Developed by Huawei engineers, this mitigation aims to make exploiting slab heap corruption vulnerabilities more difficult. By distributing the available general purpose objects for heap feng shui for any given cache size non-deterministically across up to 16 different caches, it’s harder for an attacker to target specific objects or caches for exploitation.
If you’re interested in more information, you can also follow the initial discussions over on the Linux kernel mailing list.[2][3][4]
- https://github.com/torvalds/linux/commit/3c6152940584290668b35fa0800026f6a1ae05fe
- [PATCH RFC] Randomized slab caches for kmalloc()
- [PATCH RFC v2] Randomized slab caches for kmalloc()
- [PATCH v5] Randomized slab caches for kmalloc()
Diving Into The Implementation

The time has come, I’m sure you’ve all been chomping at the bit for the last 2000 words, let’s dig into the implementation for this patch and see what the deal is.
Honestly the implementation for this mitigation is actually pretty straight forward, with only 97 additions and 15 deletions across 7 files, so more than anything it’s going to be a bit of a primer on the parts of the kmalloc API that are effected by this patchset.
We’ll follow up with a bit of an analysis on the pros and cons of the implementation tho.
Cache Setup
So first things first lets touch on how the kmalloc caches are actually created by the kernel and some of the changes needed to include the random cache copies.
The header additions include configurations for things like the number of cache copies:
+#ifdef CONFIG_RANDOM_KMALLOC_CACHES
+#define RANDOM_KMALLOC_CACHES_NR 15 // # of cache copies
+#else
+#define RANDOM_KMALLOC_CACHES_NR 0
+#endif
The [kmalloc_cache_type](https://elixir.bootlin.com/linux/v6.6/source/include/linux/slab.h#L363) enum is used to manage the different kmalloc cache types. [create_kmalloc_caches()](https://elixir.bootlin.com/linux/v6.6/source/mm/slab_common.c#L956) allocates the initial [struct kmem_cache](https://elixir.bootlin.com/linux/v6.6/source/include/linux/slub_def.h#L98) objects, which represent the slab caches we’ve been talking about, which are then stored in the exported [struct kmem_cache * kmalloc_caches[NR_KMALLOC_TYPES][KMALLOC_SHIFT_HIGH + 1]](https://elixir.bootlin.com/linux/v6.6/source/mm/slab_common.c#L677) array. As we can see from the definition, the cache type is used as one of the indexes into the array to fetch a cache, the other is the size index for that cache type (see [size_index[24]](https://elixir.bootlin.com/linux/v6.6/source/mm/slab_common.c#L692)).
With that in mind, an entry for each of the cache copies is added to [enum kmalloc_cache_type](https://elixir.bootlin.com/linux/v6.6/source/include/linux/slab.h#L363) so that they’re created and fetchable as part of the existing API:
enum kmalloc_cache_type {
KMALLOC_NORMAL = 0,
#ifndef CONFIG_ZONE_DMA
KMALLOC_DMA = KMALLOC_NORMAL,
#endif
#ifndef CONFIG_MEMCG_KMEM
KMALLOC_CGROUP = KMALLOC_NORMAL,
#endif
+ KMALLOC_RANDOM_START = KMALLOC_NORMAL,
+ KMALLOC_RANDOM_END = KMALLOC_RANDOM_START + RANDOM_KMALLOC_CACHES_NR,
#ifdef CONFIG_SLUB_TINY
KMALLOC_RECLAIM = KMALLOC_NORMAL,
#else
KMALLOC_RECLAIM,
#endif
#ifdef CONFIG_ZONE_DMA
KMALLOC_DMA,
#endif
#ifdef CONFIG_MEMCG_KMEM
KMALLOC_CGROUP,
#endif
NR_KMALLOC_TYPES
};
diff from include/linux/slab.h
The [kmalloc_info[]](https://elixir.bootlin.com/linux/v6.6/source/mm/slab_common.c#L824) is another key data structure in the kmalloc cache initialisation. This array essentially contains a [struct kmalloc_info_struct](https://elixir.bootlin.com/linux/v6.6/source/mm/slab.h#L275) for each of the kmalloc “bucket” sizes we talk about. Each element stores the size fo the bucket and the name for the various caches types of that size. E.g. kmalloc-rnd-01-64 or kmalloc-cg-64.
This array is then used to pull the correct cache name to pass to [create_kmalloc_cache()](https://elixir.bootlin.com/linux/v6.6/source/mm/slab_common.c#L661) given the size index and cache type.
I’m speeding through this, but you can probably tell already this is going to involve some macros. [INIT_KMALLOC_INFO(__size, __short_size)](https://elixir.bootlin.com/linux/v6.6/source/mm/slab_common.c#L809) is used to initialise each of the elements in kmalloc_info[], with additional macros to initialise each of the name[] elements according to type.
Below we can see the addition of the kmalloc random caches:
+#ifdef CONFIG_RANDOM_KMALLOC_CACHES
+#define __KMALLOC_RANDOM_CONCAT(a, b) a ## b
+#define KMALLOC_RANDOM_NAME(N, sz) __KMALLOC_RANDOM_CONCAT(KMA_RAND_, N)(sz)
+#define KMA_RAND_1(sz) .name[KMALLOC_RANDOM_START + 1] = "kmalloc-rnd-01-" #sz,
+#define KMA_RAND_2(sz) KMA_RAND_1(sz) .name[KMALLOC_RANDOM_START + 2] = "kmalloc-rnd-02-" #sz,
+#define KMA_RAND_3(sz) KMA_RAND_2(sz) .name[KMALLOC_RANDOM_START + 3] = "kmalloc-rnd-03-" #sz,
+#define KMA_RAND_4(sz) KMA_RAND_3(sz) .name[KMALLOC_RANDOM_START + 4] = "kmalloc-rnd-04-" #sz,
+#define KMA_RAND_5(sz) KMA_RAND_4(sz) .name[KMALLOC_RANDOM_START + 5] = "kmalloc-rnd-05-" #sz,
+#define KMA_RAND_6(sz) KMA_RAND_5(sz) .name[KMALLOC_RANDOM_START + 6] = "kmalloc-rnd-06-" #sz,
+#define KMA_RAND_7(sz) KMA_RAND_6(sz) .name[KMALLOC_RANDOM_START + 7] = "kmalloc-rnd-07-" #sz,
+#define KMA_RAND_8(sz) KMA_RAND_7(sz) .name[KMALLOC_RANDOM_START + 8] = "kmalloc-rnd-08-" #sz,
+#define KMA_RAND_9(sz) KMA_RAND_8(sz) .name[KMALLOC_RANDOM_START + 9] = "kmalloc-rnd-09-" #sz,
+#define KMA_RAND_10(sz) KMA_RAND_9(sz) .name[KMALLOC_RANDOM_START + 10] = "kmalloc-rnd-10-" #sz,
+#define KMA_RAND_11(sz) KMA_RAND_10(sz) .name[KMALLOC_RANDOM_START + 11] = "kmalloc-rnd-11-" #sz,
+#define KMA_RAND_12(sz) KMA_RAND_11(sz) .name[KMALLOC_RANDOM_START + 12] = "kmalloc-rnd-12-" #sz,
+#define KMA_RAND_13(sz) KMA_RAND_12(sz) .name[KMALLOC_RANDOM_START + 13] = "kmalloc-rnd-13-" #sz,
+#define KMA_RAND_14(sz) KMA_RAND_13(sz) .name[KMALLOC_RANDOM_START + 14] = "kmalloc-rnd-14-" #sz,
+#define KMA_RAND_15(sz) KMA_RAND_14(sz) .name[KMALLOC_RANDOM_START + 15] = "kmalloc-rnd-15-" #sz,
+#else // CONFIG_RANDOM_KMALLOC_CACHES
+#define KMALLOC_RANDOM_NAME(N, sz)
+#endif
+
#define INIT_KMALLOC_INFO(__size, __short_size) \
{ \
.name[KMALLOC_NORMAL] = "kmalloc-" #__short_size, \
KMALLOC_RCL_NAME(__short_size) \
KMALLOC_CGROUP_NAME(__short_size) \
KMALLOC_DMA_NAME(__short_size) \
+ KMALLOC_RANDOM_NAME(RANDOM_KMALLOC_CACHES_NR, __short_size) \
.size = __size, \
}
const struct kmalloc_info_struct kmalloc_info[] __initconst = {
INIT_KMALLOC_INFO(0, 0),
INIT_KMALLOC_INFO(96, 96),
INIT_KMALLOC_INFO(192, 192),
INIT_KMALLOC_INFO(8, 8),
INIT_KMALLOC_INFO(16, 16),
INIT_KMALLOC_INFO(32, 32),
INIT_KMALLOC_INFO(64, 64),
INIT_KMALLOC_INFO(128, 128),
INIT_KMALLOC_INFO(256, 256),
INIT_KMALLOC_INFO(512, 512),
INIT_KMALLOC_INFO(1024, 1k),
INIT_KMALLOC_INFO(2048, 2k),
INIT_KMALLOC_INFO(4096, 4k),
INIT_KMALLOC_INFO(8192, 8k),
INIT_KMALLOC_INFO(16384, 16k),
INIT_KMALLOC_INFO(32768, 32k),
INIT_KMALLOC_INFO(65536, 64k),
INIT_KMALLOC_INFO(131072, 128k),
INIT_KMALLOC_INFO(262144, 256k),
INIT_KMALLOC_INFO(524288, 512k),
INIT_KMALLOC_INFO(1048576, 1M),
INIT_KMALLOC_INFO(2097152, 2M)
};
diff from mm/slab_common.c
Seed Setup
Moving on, we can see how the per-boot seed is generated, which is one of the values used to randomise which cache a particular kmalloc() call site is going to end up in.
This is initialised during the initial kmalloc cache creation and is stored in the the exported symbol [random_kmalloc_seed](https://elixir.bootlin.com/linux/v6.6/source/include/linux/slab.h#L398), as we can see below:
+#ifdef CONFIG_RANDOM_KMALLOC_CACHES
+unsigned long random_kmalloc_seed __ro_after_init;
+EXPORT_SYMBOL(random_kmalloc_seed);
+#endif
...
void __init create_kmalloc_caches(slab_flags_t flags)
{
...
+#ifdef CONFIG_RANDOM_KMALLOC_CACHES
+ random_kmalloc_seed = get_random_u64();
+#endif
diff from mm/slab_common.c
It’s worth noting here the [__init](https://elixir.bootlin.com/linux/v6.6/source/include/linux/init.h#L52) and __ro_after_init annotations. The former is a macro used to tell the kernel this code is only run during initialisation and doesn’t need to hang around in memory after everything’s setup.
__ro_after_init was introduced by Kees Cook back in 2016[1] to reduce the writable attack surface in the kernel by moving memory that’s only written to during kernel initialisation to a read-only memory region.
Kmalloc Allocations
Okay, so we’ve covered how the caches are created and the seed initialisation, how are objects then actually allocated to one of these random kmalloc caches?
As we touched on, the random cache a particular allocation ends up in comes from two factors: the kmalloc() callsite and the per-boot random_kmalloc_seed:
+static __always_inline enum kmalloc_cache_type kmalloc_type(gfp_t flags, unsigned long caller)
{
/*
* The most common case is KMALLOC_NORMAL, so test for it
* with a single branch for all the relevant flags.
*/
if (likely((flags & KMALLOC_NOT_NORMAL_BITS) == 0))
+#ifdef CONFIG_RANDOM_KMALLOC_CACHES
+ /* RANDOM_KMALLOC_CACHES_NR (=15) copies + the KMALLOC_NORMAL */
+ return KMALLOC_RANDOM_START + hash_64(caller ^ random_kmalloc_seed,
+ ilog2(RANDOM_KMALLOC_CACHES_NR + 1));
+#else
return KMALLOC_NORMAL;
+#endif
diff from include/linux/slab.h
As we can see above, when calculating the kmalloc cache type for an allocation, if the flags are appropriate for the kmalloc random caches, a hash is generated from the two values mentioned and is used to calculate the kmalloc cache type (from the [kmalloc_cache_type](https://elixir.bootlin.com/linux/v6.6/source/include/linux/slab.h#L363) enum, of which there is one for each RANDOM_KMALLOC_CACHES_NR), which is then used fetch the cache from kmalloc_caches[].
static __always_inline __alloc_size(1) void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size) && size) {
unsigned int index;
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags);
index = kmalloc_index(size);
return kmalloc_trace(
- kmalloc_caches[kmalloc_type(flags)][index],
+ kmalloc_caches[kmalloc_type(flags, _RET_IP_)][index],
flags, size);
}
return __kmalloc(size, flags);
}
diff from include/linux/slab.h
We can see kmalloc() now passes the caller, using the [_RET_IP_](https://elixir.bootlin.com/linux/v6.6/source/include/linux/instruction_pointer.h#L7) macro, to kmalloc_type(). This means the unsigned long caller used to generate the hash is the return address for the kmalloc() call.
Thoughts
To wrap things up on the implementation side of things, lets discuss some of the pros and cons for KMALLOC_RANDOM_CACHES. As the config help text explains, the aim of this hardening feature is to make it “more difficult to spray vulnerable memory objects on the heap for the purpose of exploiting memory vulnerabilities.”[2].
It’s safe to say (I think), that within the context of the current heap exploitation meta and exploring the feature’s implementation, it does shake up the existing techniques commonly seen for shaping the heap and exploiting heap vulnerabilities.
On top of that, it’s a reasonably lightweight and performance friendly implementation, pretty much exclusively touching the slab allocator implementation.
It is because of that last point, though, that it is unable to provide any mitigation against the cache reuse and overflow techniques mentioned earlier, as this relies on manipulating the underlying page allocator which isn’t addressed by this patch.
As a result, in certain circumstances you could cause the free one of these random kmalloc cache slabs containing your vulnerable object and have it reallocated in a more favourable cache. Similar could be said for the cache overflow attacks.
An implementation specific point to note is on the use of the kmalloc return address (for kmalloc(), kmalloc_node(), __kmalloc() etc.) to determine which random kmalloc cache is used. If other parts of the kernel make wrappers around the slab API for their own purposes, such as [f2fs_kmalloc()](https://elixir.bootlin.com/linux/v6.6/source/fs/f2fs/f2fs.h#L3379), any objects using that wrapper can share the same _RET_IP_ from the slab allocators perspective and end up in the same cache.
What’s The New Meta?

Before we put our speculation hats on and start discussing what the new trends and techniques for heap exploitation might look like post RANDOM_KMALLOC_CACHES, it’s worth highlighting that just because it’s in the 6.6 kernel doesn’t mean we’ll see it for a while.
First of all, the 6.6 kernel is the latest release and it’ll be a while until we see this get sizeable uptake in the real world. Secondly, it’s currently an opt-in feature, disabled by default, so it really depends on the distros and vendors to enable this (and we all know that can take a while for security stuff! cough modprobe_path).
Additionally, there are a couple other mitigations out there that look to mitigate heap exploitation in different ways. This includes grsecurity’s AUTOSLAB[1] and the experimental mitigations being used on kCTF by Jann Horn and Matteo Rizzo (which I’d love to get into here, perhaps another post?!)[2]. These could potentially see more uptake in the long run than RANDOM_KMALLOC_CACHES, or vice versa.
But if we were interested in tackling heap exploitation in a RANDOM_KMALLOC_CACHES environment, what might it look like? As we mentioned, this implementation focuses on the slab allocator and doesn’t really touch the page allocator. As a result, the kernel is still vulnerable to cache reuse and overflow attacks.
So perhaps we see a world where “generic techniques” shift to finding new page allocator feng shui primitives, which has had less focus, to streamline the cache reuse/overflow approaches and gain LPE or perhaps to leak the random seed.
It’s hard to say this early on, and without spending more time on the problem, whether we’d shift into a new norm of generic techniques and approaches for page allocator feng shui as a result of this kind of slab hardening, or whether due to the constraints that’s simply infeasible and the shift will be to more bespoke chains per bug (which could be considered quite a win for hardening’s sake).
That said, I’m sure the same was said about previous hardening features so who knows!
- https://grsecurity.net/how_autoslab_changes_the_memory_unsafety_game
- https://github.com/thejh/linux/blob/slub-virtual-v6.1-lts/MITIGATION_README
Wrapping Up

Wow, we made it to the end! A 4k word deep dive into a new kernel mitigation certainly is one way to get back into the swing of things, hopefully it made a good read though :)
We talked about the new kernel mitigation RANDOM_KMALLOC_CACHES and gave some context into the problems its trying to address. Loaded with that information we explored the implementation and how that might impact current heap exploitation techniques.
I would have liked to have spent more time tinkering with the mitigation in anger and perhaps including some demos or experiments, but being realistic about my time and availability, I figured it’d be good to get this out rather than maybe get that out.
That said, maybe I’ll try write up some old heap ndays on a RANDOM_KMALLOC_CACHES=y system to try and demonstrate the different approaches required. That sounds quite fun!
Equally, I quite liked doing a breakdown and review of a new kernel feature, so perhaps I’ll do some more of that going forward (maybe the kCTF experimental mitigations???).
Anyways, you’ve endured enough of my waffling, thanks for reading! As always feel free to @me if you have any questions, suggestions or corrections :)
exit(0);